
The Memo - 30/Jan/2025
MatterGen + TaCr2O6, Stargate Project, DeepSeek-R1, and much more!

To: US Govt, major govts, Microsoft, Apple, NVIDIA, Alphabet, Amazon, Meta, Tesla, Citi, Tencent, IBM, & 10,000+ more recipients…
From: Dr Alan D. Thompson <LifeArchitect.ai>
Sent: 30/Jan/2025
Subject: The Memo - AI that matters, as it happens, in plain English
AGI: 88%
ASI: 0/50 (no expected movement until post-AGI)Alan, 1½ years ago (The sky is entrancing, Jun/2023):
Whether it’s 1 billion or 100 billion or even a trillion dollars of investment… any organization that leads us to artificial general intelligence has untold value. But, in a post-scarcity world—and perhaps in a post-capitalist world and a post-money world—that value will not be measured in dollars…
I would be throwing everything at AI models right now: pushing as much data, PhD-level brain power, and massive computer processing as possible. Entire countries and governments could help fund and insulate this…
Whatever resources are necessary can and should be applied, and on the other side will be… something even more ‘miraculous’ than the neutered ChatGPT or the more powerful GPT-4 engine. When companies get to the next phase of AI, how much they’ve invested will not even be a matter of discussion. We will be in a completely new world.
The winners of The Who Moved My Cheese? AI Awards! for Jan/2025 were several publishers at the Chennai International Book Fair, including Christian Weiss from German publisher Draupadi Verlag. (‘I cannot imagine AI translating poetry… AI always repeats something that is already here. So, I think AI cannot compete with human beings in being creative and inventing new forms of writing.’). Imagine going on record with a statement like that in 2025…
In the previous edition of The Memo (11/Jan/2025), I included an empirical piece on brain atrophy due to LLM use. Parallel to the release of that edition, researchers at the Swiss Business School published their latest paper in the same area. The evidence-based findings echo my piece: a significant correlation between frequent AI tool usage and lower critical thinking abilities due to cognitive offloading.
Read ‘AI Tools in Society: Impacts on Cognitive Offloading and the Future of Critical Thinking‘: https://www.mdpi.com/2075-4698/15/1/6
Contents
The BIG Stuff (MatterGen, Stargate, R1, 14110 revoked, 3GW datacentre…)
The Interesting Stuff (OpenAI Operator, MiniMax, Even more Google Veo 2…)
Policy (Abu Dhabi $1.5T, Anthropic ISO 42001, US Gov AI infrastructure + 2nm…)
Toys to Play With (Sex with ChatGPT, best AI image upscaler, Trae IDE…)
Flashback (Capitalism and post-scarcity…)
Next (Grok-3, o3, Anthropic-Next, Llama 4, Gemini 3.0, o4, Roundtable…)
The BIG Stuff
MatterGen: a new paradigm of materials design with generative AI (16/Jan/2025)
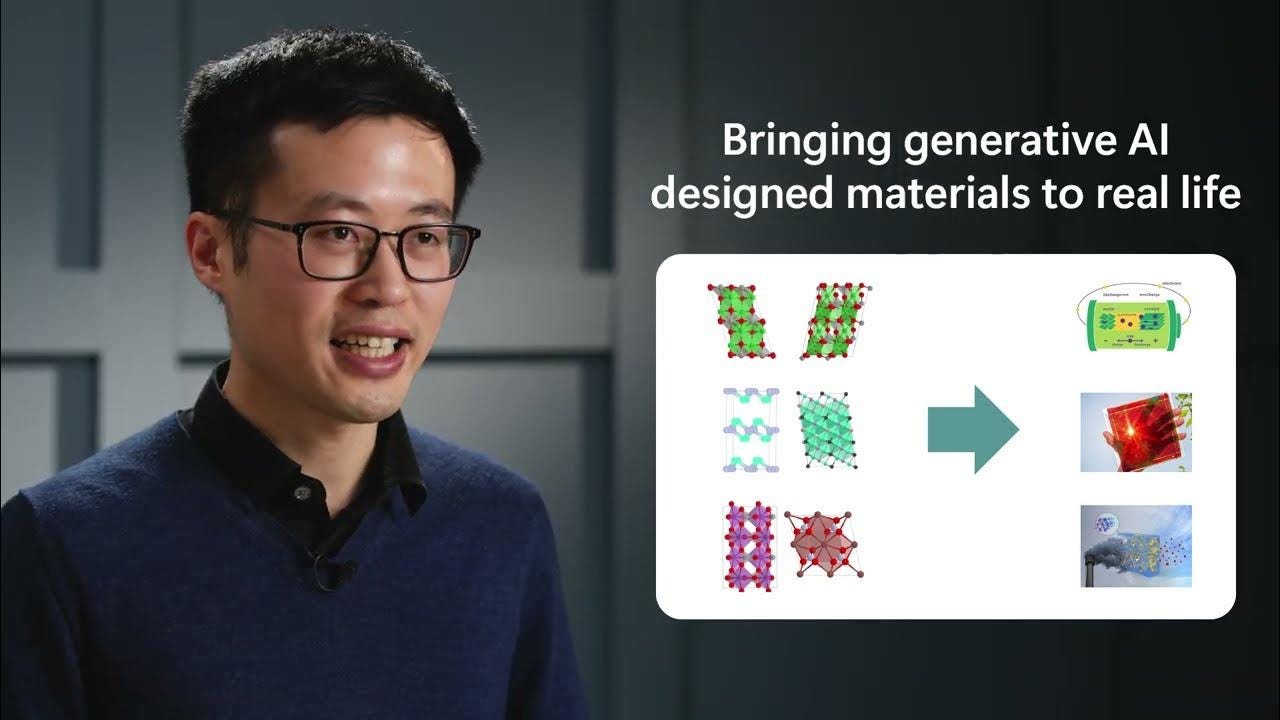
MatterGen is a groundbreaking generative AI tool developed by Microsoft Research that revolutionizes materials discovery by generating novel materials based on design prompts.
…we synthesized a novel material, TaCr₂O₆ whose structure was generated by MatterGen… a model that generates stable, diverse inorganic materials across the periodic table…
Unlike traditional screening methods, MatterGen utilizes a diffusion model to efficiently explore and create materials with specific chemical, mechanical, electronic, or magnetic properties by manipulating their 3D geometry. This approach has the potential to significantly impact various fields, including the development of batteries and solar cells, by accessing the full space of unknown materials.
Read more via Microsoft Research blog.
Download the new paper (PDF, 24 pages, 12MB), view the repo, watch an older video.
This discovery turns one of my ASI checklist items amber, though obviously we need to wait for post-AGI + superintelligence for a ‘green light’: https://lifearchitect.ai/asi
OpenAI Stargate Project + competing datacentres (21/Jan/2025)
Stargate Site 1. Texas, USA on 875 acres (about the size of NYC Central Park). Jan/2025.
The Stargate Project is a new company which will invest US$500B to build new AI infrastructure for OpenAI in the United States. The initiative is run by OpenAI in collaboration with SoftBank, Oracle, and other partners, with plans to invest the money on datacentres over the next four years, with initial operations starting in Texas. Dr Noam Brown from OpenAI remarked:
This is on the scale of the Apollo Program and Manhattan Project when measured as a fraction of GDP. This kind of investment only happens when the science is carefully vetted and people believe it will succeed and be completely transformative. I agree it’s the right time. (21/Jan/2025)
OpenAI announce: https://openai.com/index/announcing-the-stargate-project/
It has a Wikipedia page, too: https://en.wikipedia.org/wiki/The_Stargate_Project
Meta’s CEO parried with:
In 2025, I expect Meta AI will be the leading assistant serving more than 1 billion people, Llama 4 will become the leading state of the art model, and we'll build an AI engineer that will start contributing increasing amounts of code to our R&D efforts.
To power this, Meta is building a 2GW+ datacentre that is so large it would cover a significant part of Manhattan. We'll bring online ~1GW of compute in '25 and we'll end the year with more than 1.3 million GPUs. We're planning to invest $60-65B in capex this year while also growing our AI teams significantly, and we have the capital to continue investing in the years ahead.
Read Zuckerberg’s post (24/Jan/2025).
On the other side of the world, China has been discussing investing between US$137B (Jan/2025) and US$1.4T (Sep/2024) into their AI industry.
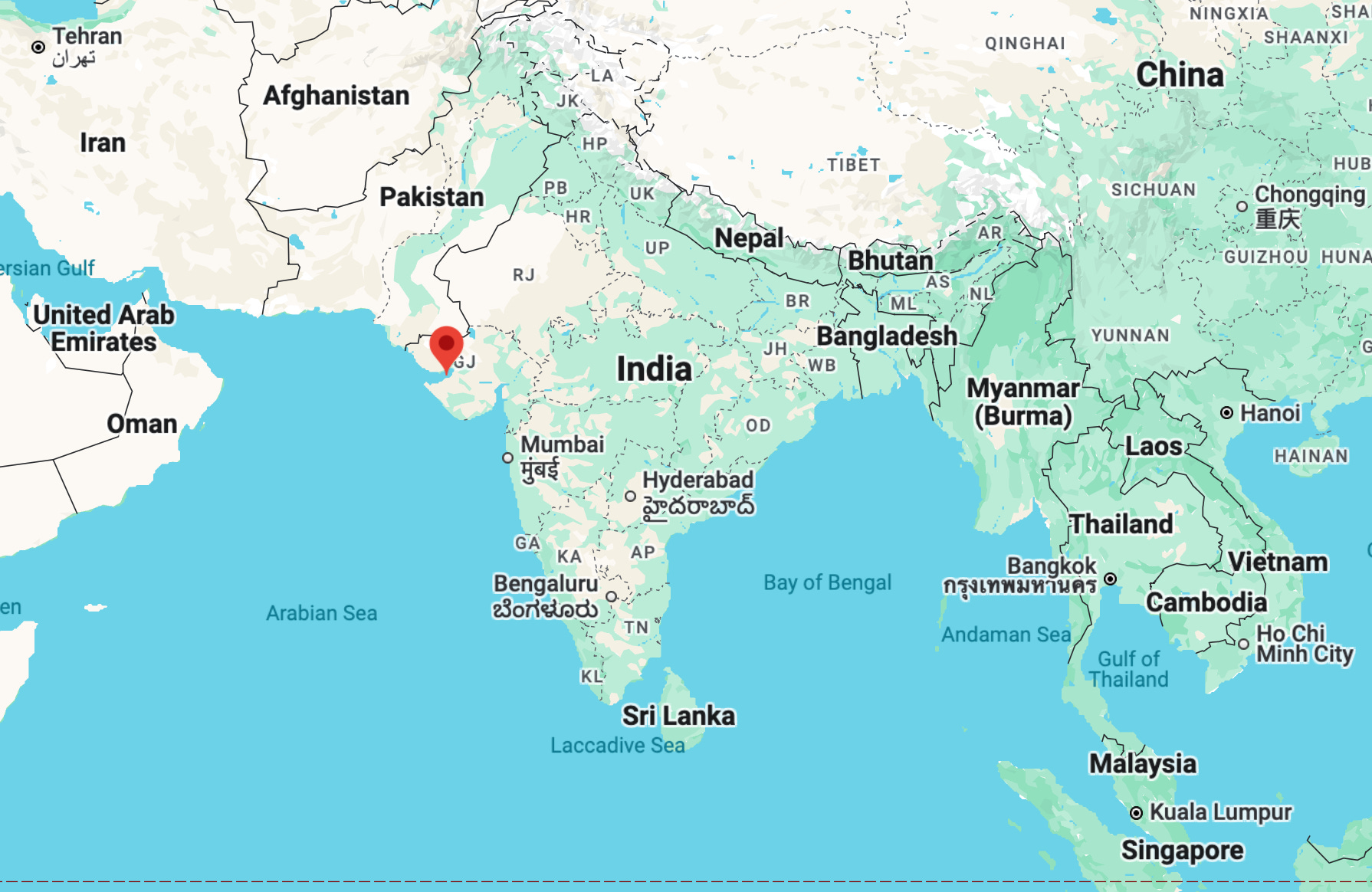
In Gujarat, India, Mukesh Ambani’s Reliance Group is set to construct what could be the world’s largest datacentre. The facility in Jamnagar (pronounced jam·nuh·gaa) is expected to use NVIDIA’s AI semiconductors and to have a total capacity of three gigawatts (3GW).
Read more via Bloomberg, 23/Jan/2025.
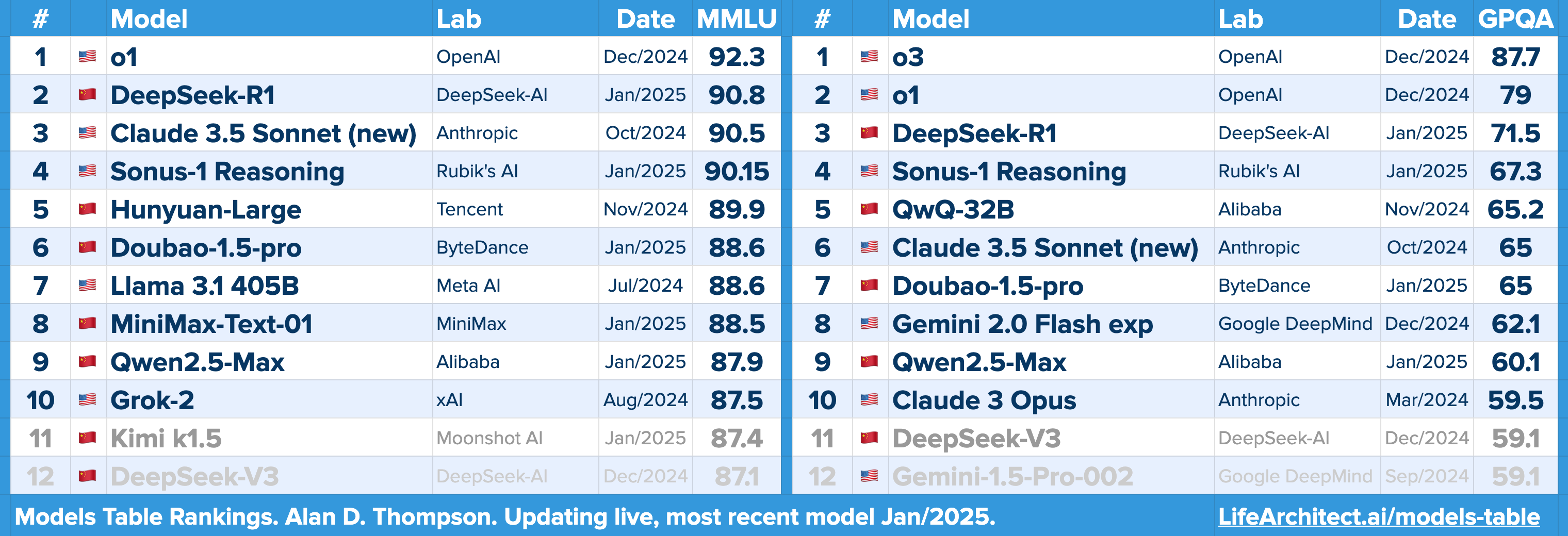
Model Table Rankings update (Jan/2025)
Readers of The Memo will be unsurprised by the continuing success of Chinese AI labs, as we’ve been covering China since day one. This month, Chinese AI labs launched five different frontier models (updated after this edition went out: R1, Doubao-1.5-pro, Qwen2.5-Max, MiniMax, k1.5), with most of them taking positions in the top 10 models worldwide. This is easily visible in my new Models Table Rankings (updated live): https://lifearchitect.ai/models-table/
This kind of shift in frontier models hasn’t happened at this speed before, but makes perfect sense in the context of exponential growth. Here’s that chart again:
With all the surrounding media overreaction, stock market chaos (and subsequent recovery), and Joe Public commentary, I guess we have to talk about DeepSeek-R1. We first covered Hangzhou-based DeepSeek-AI more than a year ago in The Memo edition 24/Jan/2024. DeepSeek-R1 is their new reasoning model, like OpenAI’s o1 and o3, but open source. It scores high on benchmarks (MMLU=90.8, GPQA=59.1), and the ALPrompts (2024H1=5/5, 2024H2=5/5, 2025H1=0/5 the same score as o1).
Sidenote: I tested using the faster R1 hosted by Fireworks on Poe for data safety. Fireworks AI is headquartered in California, USA, so I’m more confident that DeepSeek won’t be using my ALPrompt results for training its next model…
DeepSeek trained R1 using 50,000 NVIDIA H100s or similar Hopper cards (Dylan, Nov/2024 & Scale, Jan/2025). It is worth reading the paper, and even uploading it to R1 to discuss the paper with you!
Playground in China, playground in US, paper, HF, repo, Models Table.
Allen AI’s Dr Nathan Lambert wrote the clearest technical analysis of R1 (Jan/2025) and the V3 base model (Dec/2024).
Here are my main takeaways from DeepSeek-R1 and the other big Chinese models this month:
China has been keeping pace this whole time. Chinese AI labs have been contributing to the LLM race since at least early 2021 with Huawei and Baidu’s offerings. This means they have the same breadth of experience as the US AI labs (which are staffed by a strong presence of Chinese scientists anyway).
Bigger is still better. Ignore the media. Yes, R1 is popular, but it’s not even in the top 10 most interesting models of the last 12 months. The base model (V3, 685B MoE) may have been trained with a smaller compute budget than the current frontier models. Still, industry analysis reveals that DeepSeek might be concealing the full scale of its GPU inventory, and actually has access to around $1.5B of NVIDIA hardware for training and inference, plus the new Huawei 910C chips for inference. The R1 paper (p15) underscores that big spending for big smarts is still necessary: ‘…advancing beyond the boundaries of intelligence may still require more powerful base models and larger-scale reinforcement learning’. That is a truism if I’ve ever seen one.
Generosity makes greedy labs look (more) foolish. Recent open-source LLM releases reveal just how embarrassing and disappointing the leading ‘closed’ AI labs really are (especially DeepMind, Anthropic, and OpenAI). OpenAI hasn’t released an open LLM to the public since GPT-2 (2019). Both DeepMind and Anthropic have never released an open LLM to the public. Greed and paternalism are indefensible in the age of AI.
Reinforcement learning matches how prodigies develop. The development of gifted children provides a fascinating lens for understanding R1’s learning process. Dr Andrej Karpathy articulated this nicely (28/Jan/2025):
There are two major types of learning, both in children and in deep learning:
Imitation learning (watch and repeat, i.e., pretraining, supervised finetuning)
Trial-and-error learning (reinforcement learning)
My favorite simple example is AlphaGo:
1 is learning by imitating expert players.
2 is reinforcement learning to win the game.
Almost every single shocking result of deep learning—and the source of all magic—is always 2. 2 is significantly, significantly more powerful. 2 is what surprises you.
2 is when the paddle learns to hit the ball behind the blocks in Breakout.
2 is when AlphaGo beats even Lee Sedol.
2 is the "aha moment" when the DeepSeek (or o1, etc.) discovers that it works well to re-evaluate assumptions, backtrack, try something else, etc.
It's the solving strategies you see the model use in its chain of thought. It's how it goes back and forth, thinking to itself. These thoughts are emergent (!!!), and this is actually seriously incredible, impressive, and new (as in publicly available, documented, etc.).
The model could never learn this with 1 (by imitation) because the cognition of the model and the cognition of the human labeler are different. The human would never know how to correctly annotate these kinds of solving strategies or what they should even look like. They have to be discovered during reinforcement learning as empirically and statistically useful towards a final outcome.
Reuters: Trump revokes Biden executive order on addressing AI risks (20/Jan/2025)
US President Donald Trump has revoked a 2023 executive order by former President Joe Biden that aimed to mitigate risks associated with AI. Biden’s order mandated that AI developers, whose systems could threaten national security or public safety, share safety test results with the US government.
President Biden’s Executive Order 14110 on the Safe, Secure and Trustworthy Development and Use of Artificial Intelligence specified 10^26 FLOPs [100 septillion FLOPs, about $70M training budget] as the threshold for reporting obligations to the US Federal Government (Section 4.2(b)(i)), and had been described (31/Oct/2023) as an ‘AI Red Tape Wishlist,’ that would have ended up ‘stifling new companies and competitors from entering the marketplace, and significantly expanding the power of the federal government over American innovation.’
Read more via Reuters.
See the official statement (find in page: ‘14110’): whitehouse.gov.
Did you know? The Memo features in Apple’s recent AI paper, has been discussed on Joe Rogan’s podcast, and a trusted source says it is used by top brass at the White House. Across over 100 editions, The Memo continues to be the #1 AI advisory, informing 10,000+ full subscribers including Microsoft, Google, and Meta AI. Full subscribers have complete access to the entire 4,500 words of this edition!
The Interesting Stuff
Exclusive: Benchmarks are catching up with my BASIS scaffolding (Jan/2025)
In The Memo edition 17/Sep/2024, we discussed a new benchmark called ‘Humanity’s Last Exam’ (HLE) to challenge AI systems with difficult questions that extend beyond current benchmark tests. The project is led by Dr Dan Hendrycks from the Center for AI Safety, with Scale AI, and the benchmark has now been released.