
The Memo - 9/Jul/2023
Microsoft LongNet, Salesforce XGen, OpenAI London, and much more!

FOR IMMEDIATE RELEASE: 9/Jul/2023
Prof Ray J. Solomonoff, 1985 (PDF):
The last 100 years have seen the introduction of special and general relativity, automobiles, airplanes, quantum mechanics, large rockets and space travel, fission power, fusion bombs, lasers, and large digital computers. Any one of these might take a person years to appreciate and understand. Suppose that they had all been presented to mankind in a single year! This is the magnitude of ‘future shock’ that we can expect from our AI expanded scientific community. In the past, introduction of a new technology into the culture has usually been rather slow, so we had time to develop some understanding of its effect on us, to adjust the technology and culture for an optimum ‘coming together’…
What seems most certain is that the future of man—both scientific and social—will be far more exciting than the wildest eras of the past.
Welcome back to The Memo.
While this is another huge edition (perhaps we could call it the OpenAI edition!), I am relieved to announce a gentle easing in the AI news cycle. After the first half of 2023 saw a record 30 editions of The Memo (that’s more than one edition per week), 47 new model highlights including the massive releases of OpenAI GPT-4 and Google PaLM 2, I can see my bed on the distant horizon…
While the pace of change is actually increasing, I believe that this ‘eye of the storm’ is a short moment of solace before imminent releases of multi trillion-parameter models including Google DeepMind Gemini (my link), OpenAI GPT-5 (my link), Anthropic Claude-Next, and many more.

We’re featuring a longer Policy section in this edition, including the latest US defense use cases for large language models.
In the Toys to play with section, we look at the latest dialogue model with voice in and voice out (like Her), the latest AI audio processor, a new AI Junior Developer, Glass AI, Midjourney’s new panning functionality, and more…
The BIG Stuff
Microsoft LongNet increases sequence length to 1 billion tokens (6/Jul/2023)
Our work opens up new possibilities for modeling very long sequences, e.g., treating a whole corpus or even the entire Internet as a sequence…
Sequence length, as the last atomic dimension of the neural network, is desirable to be unlimited. Breaking the limitation of sequence length introduces significant advantages. First, it provides large memory and receptive field for models, which is practical for them to interact with human and the world. Second, a longer context contains more complex causality and reasoning paths that models can exploit in training data. In contrast, short dependency has more spurious correlations, which is harmful to generalization. Third, it enables to explore the limits of in-context learning.
As an interesting aside, all researchers on this paper (there are seven of them) are from the Natural Language Computing Group at Microsoft Research Asia, Beijing, China. The output from both AI labs in China and Chinese researchers working in Western AI labs is phenomenal.
Read the paper: https://arxiv.org/abs/2307.02486
Salesforce launches XGen 7B (Jul/2023)
XGen was trained on 1.5T tokens to 7B parameters. That’s 215:1, far outpacing the recommended ratio of tokens to parameters proposed by Chinchilla (20:1) and reinforced by recent models like LLaMA (22:1). The Salesforce team collected a significant corpus from recent datasets like RedPajama, The Pile, and C4.
Salesforce found that training to 7B parameters gave them a ‘training cost of $150K on 1T tokens under Google Cloud pricing for TPU-v4.’
Read more: https://blog.salesforceairesearch.com/xgen/
Github repo: https://github.com/salesforce/xGen?ref=blog.salesforceairesearch.com
See it on my timeline: https://lifearchitect.ai/timeline/
See it in my models table: https://lifearchitect.ai/models-table/
OpenAI prepares for superintelligence (5/Jul/2023)
Currently, we don't have a solution for steering or controlling a potentially superintelligent AI, and preventing it from going rogue. Our current techniques for aligning AI, such as reinforcement learning from human feedback, rely on humans’ ability to supervise AI. But humans won’t be able to reliably supervise AI systems much smarter than us.
Our goal is to build a roughly human-level automated alignment researcher. We can then use vast amounts of compute to scale our efforts, and iteratively align superintelligence.
Read more via OpenAI: https://openai.com/blog/introducing-superalignment
I’ve recently covered superintelligence and RLHF in detail:
Fine-tuning on human preferences is a fool’s errand
Just as ‘democracy is the worst form of Government,’ so too is fine-tuning based on human preferences the worst form of alignment (for now). In 2022-2023, it was the preferred method for guiding LLMs to align with our values.
But the cost is significant.
…In plain English, no human is smart enough to guide superintelligence. So, putting a human in the loop to ‘rate’ multiple choices of an AI output and then choose the ‘best’ option is an inherently flawed process. It should be noted that the humans tasked with providing this guidance are from parts of Africa and are paid ‘approximately $1 per hour, and sometimes less’ (21/May/2023).
Read more: https://lifearchitect.ai/alignment/#rlhf
The luddites are here (Jul/2023)

A decentralized group of safe streets activists in San Francisco realized they can disable Cruise and Waymo robotaxis [full self-driving vehicles] by placing a traffic cone on a vehicle’s hood, and they’re encouraging others to do it, too…
Other opponents like the San Francisco Taxi Workers Alliance and the Alliance for Independent Workers have protested the spread of robotaxis, which they say will eliminate the need for taxi and ride-hail drivers.
Ray Kurzweil predicted this level of ‘intelligence’ 23 years ago. This brief excerpt is from his book The Age of Spiritual Machines: When Computers Exceed Human Intelligence (Jan/2000):
The weavers of Nottingham enjoyed a modest but comfortable lifestyle from their thriving cottage industry of producing fine stockings and lace. This went on for hundreds of years, as their stable family businesses were passed down from generation to generation. But with the invention of the power loom and the other textile automation machines of the early eighteenth century, the weaversʹ livelihoods came to an abrupt end. Economic power passed from the weaving families to the owners of the machines.
Into this turmoil came a young and feebleminded boy named Ned Ludd, who, legend has it, broke two textile factory machines by accident as a result of sheer clumsiness. From that point on, whenever factory equipment was found to have been mysteriously damaged, anyone suspected of foul play would say, ʺBut Ned Ludd did it.ʺ
…The Luddite philosophy remains very much alive as an ideological inclination, but as a political and economic movement, it remains just below the surface of contemporary debate. The public appears to understand that the creation of new technology is fueling the expansion of economic well‐being.
The only way for the species to keep pace will be for humans to gain greater competence from the computational technology we have created, that is, for the species to merge with its technology.
Not everyone will find this prospect appealing, so the Luddite issue will broaden in the twenty‐first century from an anxiety about human livelihoods to one concerning the essential nature of human beings. However, the Luddite movement is not likely to fare any better in the next century than it has in the past two. it suffers from the lack of a viable alternative agenda.
…a reflexive opposition to technology is not very fruitful in todayʹs world. It is important, however, to recognize that technology is power. We have to apply our human values to its use.
…the challenge to the human race posed by machines is fundamental enough that a violent reaction during this coming century is a strong possibility.
Exclusive: 5,000 AI papers per month or 166 papers per day (6/Jul/2023)

Remember this chart from Sep/2022? It shows the number of AI papers published per month since the 1990s. It was designed by a group of researchers from Max Planck and elsewhere. To provide an update, I had a dig around arxiv—their Tableau data lake is broken or at least wildly inaccurate, so I had to do it by hand.
The original Sep/2022 paper used these arxiv paper categories: cs.AI, cs.LG, cs.NE, and stat.ML.
My maths as of 6/Jul/2023:
cs.ai: 9888
cs.lg: 16354
cs.ne: 859
stat.ml: 2850
= 29,951 papers in first 6 months of 2023
≈ 4,991 papers per month
≈ 166 papers per day
≈ 7 papers per hour
In summary, it seems impossible for any single human to read and comprehend 166 academic papers per day (some hitting several hundred pages each)… and it’s getting worse. Welcome to the near-vertical take-off of AI!
UPDATE AUG/2024: Some of my numbers were overestimated by 2-3× in this analysis due to duplicated Tableau data. I now use the raw data as shown on pages like this:
Year: https://arxiv.org/list/cs.AI/2024 (“Total of x entries")
Day: https://arxiv.org/list/cs.AI/recent?skip=259&show=25 (“Total of x entries”)
GPT-4 API available, davinci and text-davinci-003 to be deprecated (6/Jul/2023)
OpenAI have announced general availability of GPT-4 via API.
Read more: https://openai.com/blog/gpt-4-api-general-availability
They’ve also announced the deprecation and sunsetting of the original base GPT-3 davinci model (released in 2020, and powering Leta AI since 2021), as well as the popular text-davinci-003 model.
As part of our increased investment in the Chat Completions API and our efforts to optimize our compute capacity, in 6 months we will be retiring some of our older models using the Completions API. While this API will remain accessible, we will label it as “legacy” in our developer documentation starting today. We plan for future model and product improvements to focus on the Chat Completions API, and do not have plans to publicly release new models using the Completions API.
Starting January 4, 2024, older completion models will no longer be available, and will be replaced…
If the replacement of davinci with davinci-002 goes the way I think it’s going to go, this is a major turning point for openness and consistency in model output. The deletion of the world’s most popular base model (no safety, no fine-tuning) in GPT-3 davinci—powering everything from Jasper.ai to Leta AI—is wholly unexpected, and a big nail in the coffin for OpenAI.
One saving grace could be OpenAI’s upcoming release of an open-source model (Reuters, 15/May/2023) with the power of the 2020 GPT-3 davinci base model. But this is probably just my wishful thinking.
Read more: https://platform.openai.com/docs/deprecations
See my viz of 64 models in the GPT-3 family to Mar/2023.
The Interesting Stuff
China continues launching new models (Jul/2023)
Huawei has announced a new Pangu model with 100B parameters.
The architecture is complex, though reminds me of OpenAI’s goal of providing personalized models for everyone:
Pangu 3.0 has a three-tier architecture. The foundation layer, L0, has five different models: natural language processing, multimodal databases, computer vision, prediction and scientific computing. L0 provides various skills to meet the needs of different industry scenarios.
The second layer, L1, provides a variety of industry-specific models, focusing on fields such as e-government, finance, manufacturing, mining and meteorology.
The third layer, L2, provides multiple scenario-specific models for particular industry applications or business scenarios.
Customers can also train models using their own datasets based on Huawei's L0 or L1 Pangu layers. (China.org.cn, 8/Jul/2023)
For a closer look at large language models from this invisible region (according to Western media!), The Centre for the Governance of AI (GovAI) has issued a report that analyzes 26 large-scale pre-trained AI models developed in China (Apr/2023).
Download ‘Recent Trends in China’s Large Language Model Landscape‘ (14 pages, PDF).
Google Med-PaLM 2 annotated paper (3/Jul/2023)
I’ve spent some time with Google’s Med-PaLM 2 paper. It is a harrowing read!
Med-PaLM 2 outperforms even the massive GPT-4, and Med-PaLM 2’s outputs are vastly preferred to those of human doctors.
While most forums and media are busy with all the possibilities of things going wrong, here is a very striking chart, showing just how ‘right’ things are going. It’s a dizzying view of just far we’ve come since GPT-3 in 2020, and how little time left ‘we’ (raw humans) have before augmentation takes over. Keep in mind that these models are often being tested on new, unreleased exams, and OpenAI showed that GPT-4 could not have memorized any of the data during training. It’s a demonstration of true intelligence, applied to a critical sector.

See the Med-PaLM 2 annotated paper and all annotated papers + report cards.
Watch my video with Harvey Castro MD (link):
Learn more about AI via Microsoft and LinkedIn (Jul/2023)
Microsoft and LinkedIn have launched a new generative AI course with certificate.
As part of our Skills for Jobs program, we're partnering with LinkedIn Learning to launch the first Professional Certificate on Generative AI in the online learning market. Through this new coursework, workers will learn introductory concepts of AI, including a look at responsible AI frameworks, and receive a Career Essentials certificate when they pass the assessment. This Professional Certificate on Generative AI is currently available in English and will launch in Spanish, Portuguese, French, German, Simplified Chinese, and Japanese over the coming months on LinkedIn Learning.
For even more options, here are five of my top online AI courses:
Zero to Hero course by Andrej Karpathy - YT (Jun/2023).
Machine Learning Specialization with Andrew Ng - Coursera (2022).
Other Stanford online options - YT (2019-2023).
Oh, and for a very simplified and high-level view, full subscribers to The Memo get access to my short online seminar for Iceland + GPT-4 (2023).
Generative AI in Finance and Beyond (May/2023)
I enjoyed the real-world angle of this chart from WhiteSight:

Grab the original image or read the source article.
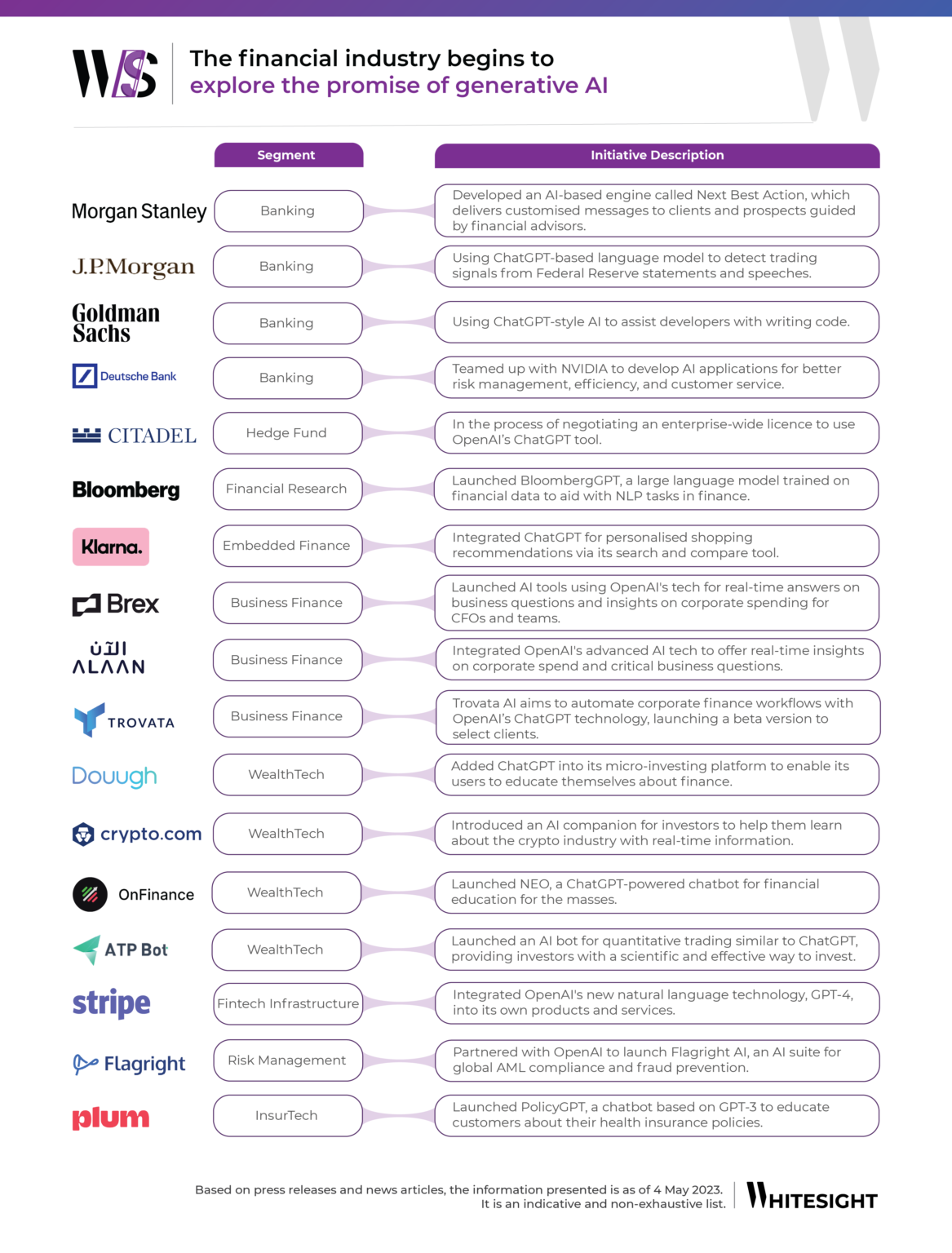{kind=link}
Harvard course requires AI use (Jul/2023)
I reported on the use of AI within Wharton (UPenn) back in The Memo edition 27/Jan/2023, where student use of ChatGPT and image generation tools is mandatory as part of the AI policy. Harvard has followed suit with their unit CS50: Introduction to Computer Science.
Malan wrote that CS50 has always incorporated software, and called the use of AI “an evolution of that tradition.” Course staff is “currently experimenting with both GPT 3.5 and GPT 4 models,” Malan wrote.
“Our own hope is that, through AI, we can eventually approximate a 1:1 teacher:student ratio for every student in CS50, as by providing them with software-based tools that, 24/7, can support their learning at a pace and in a style that works best for them individually”…
Read more: https://www.thecrimson.com/article/2023/6/21/cs50-artificial-intelligence/
ChatGPT officiates wedding (5/Jul/2023)

This one is certainly interesting!
ChatGPT planned the welcome, the speech, the closing remarks — everything except the vows — making ChatGPT, in essence, the wedding officiant.
I maintain a list of achievements by GPT-4 and ChatGPT (GPT-3.5), from helping judges with verdicts, to passing quantum computing exams.
Take a look at ChatGPT’s list of achievements.
Policy
Jack Clark, former Policy Director of OpenAI (26/Jun/2023):
You can think of global AI policy as being defined by three competing power blocs - there's the Asian bloc which is mostly defined by China and mostly locally focused for now (using AI to grow its economy and better compete economically), the European bloc which is defined by politicians trying to craft a regulatory structure that will be templated around the planet and thereby give them soft power, and the USA bloc which is, as with most US policy, focused on growing its economic might and maintaining hegemonic dominion through use of advanced technology.
US continues LLM integration with defense (Jul/2023)
We talked about Palantir’s defense offering back in The Memo 30/Apr/2023 edition.
The newest contender is Scale AI’s Donovan platform, currently backed by Cohere’s Command 52B model, Anthropic Claude 52B, GPT-Scale-6B (USG Aligned), and more.
It lists the following US departments and agencies as users:
Central Intelligence Agency (CIA).
US Air Force.
DOD Chief Digital and Artificial Intelligence Office (CDAO).
Air Force Research Laboratory.
XVIII Airborne Corps.
Matthew Strohmeyer is sounding a little giddy. The US Air Force colonel has been running data-based exercises inside the US Defense Department for years. But for the first time, he tried a large-language model to perform a military task.
“It was highly successful. It was very fast,” he tells me a couple of hours after giving the first prompts to the model. “We are learning that this is possible for us to do.”
…In a demonstration based on feeding the model with 60,000 pages of open-source data, including US and Chinese military documents, Bloomberg News asked Scale AI’s Donovan whether the US could deter a Taiwan conflict, and who would win if war broke out. A series of bullet points with explanations came back within seconds. (Bloomberg, 6/Jul/2023)
While I find this use case fairly depressing, the demonstration video is very detailed, showing analysis of ships and aircraft around Taiwan, with examples in several fields and multiple languages.
Read more: https://scale.com/donovan
Watch the video demo by Scale AI (link):
European companies claim the EU’s AI Act could ‘jeopardise technological sovereignty’ (1/Jul/2023)
Over 150 executives from companies like Renault, Heineken, Airbus, and Siemens have signed an open letter urging the EU to rethink its plans to regulate AI.
Read the article via The Verge.
UK universities draw up guiding principles on generative AI (5/Jul/2023)
The five guiding principles state that universities will support both students and staff to become AI literate; staff should be equipped to help students to use generative AI tools appropriately; the sector will adapt teaching and assessment to incorporate the “ethical” use of AI and ensure equal access to it; universities will ensure academic integrity is upheld; and share best practice as the technology evolves.
OpenAI completes world tour (Jul/2023)
…for four weeks in May and June, an OpenAI team led by our CEO Sam Altman traveled to 25 cities across 6 continents to speak with users, developers, policymakers, and the public…
In Nigeria, high school students told us how they used ChatGPT to help break down complicated study topics. In Singapore, civil servants are incorporating OpenAI tools to provide public services more efficiently. In France, a grocery chain is using our tools to help customers reduce food waste and developers are using our tools to make code more efficient and secure.
Read more: https://openai.com/blog/insights-from-global-conversations
OpenAI announces London office (Jul/2023)
London’s vibrant technology ecosystem and its exceptional talent make it the ideal location for OpenAI’s first international office. The teams in London will focus on advancing OpenAI’s leading-edge research and engineering capabilities while collaborating on our mission with local communities and policy makers.
Read more: https://openai.com/blog/introducing-openai-london
Toys to Play With
Pi with voice (8/Jul/2023)
Inflection has released Pi for iOS with voice in (speech-to-text). That means it is now a true dialogue agent that can listen and talk to you. The app is still free, and I’ve estimated that the underlying model—Inflection-1—is around 120B parameters.
Grab it: https://pi.ai/ios
AI Junior Developer: Sweep AI in GitHub (Jul/2023)
We built Sweep by integrating search + GPT4-32k [and Claude 100k] into Github. You can tell Sweep about bugs and feature requests and Sweep will create a PR with code changes. Then anywhere GitHub takes text (PR comments, code comments), Sweep can read it and tweak the PR.
Check it out: https://github.com/sweepai/sweep#-getting-started
Descript Studio Sound is better than Adobe Enhance (2022)
I used Adobe Enhance for the audio remastering of Leta AI episodes 0-5.
There are several other options, including this one by Descript.
Try it: https://www.descript.com/studio-sound
Watch (listen to) the video (link):
Glass AI for medicine (2023)
Glass AI is an experimental product in development. It leverages a foundational large language model (GPT-4) to generate a differential diagnosis or draft clinical plan based on a submitted clinical problem representation. The foundational large language model is combined with context, including evidence-based guidelines, schemas, and case studies, created by clinicians at Glass Health to achieve a high level of clinical excellence in our AI outputs.
Take a look: https://glass.health/ai
Midjourney adds panning (4/Jul/2023)

Outpainting, zooming, and now panning. Check it out!
Try it out: https://www.midjourney.com/
Leta, GPT-3 AI - Analyzing Leta with GPT-4 + ChatWithPDF plugin (Jul/2023)
I’ve been wanting to do this for a while! Thanks to Denise for cleaning and finalising the massive 400-page transcript.
Tech stack: GPT-4 + ChatWithPDF plugin for analysis, voice is 'Bryan Lee Jr.' by Genny, viz of voice is by VEED.
Watch my video (link):
Flashback: Roadmap: AI’s next big steps in the world (Jul/2022)
One year ago this month…
The next step will be giant. In the year 1666, one might feel privileged to observe Isaac Newton as he came up with some of our modern understandings of the physical world. In the year 1700, it would have been amazing to sit next to Johann Sebastian Bach as the Baroque period took off. I’m certain that it would have been shocking to watch Orville and Wilbur Wright flying around in the early 1900s.
As it is, you have access to an even better experience right now.
You are here…
You have a front row seat to the most exciting period in human history.
Read more: https://lifearchitect.ai/roadmap/
Next
I’m watching new model releases very carefully, as we continue to train with 10x more data than 2021-era models, with increasingly effective outputs and achievements unlocked.
You can track these in realtime on the models table: https://lifearchitect.ai/models-table/
We’re also trialling comments for this edition.
All my very best,
Alan
LifeArchitect.ai