
The Memo - 31/Jan/2024
Neuralink Telepathy, gold datasets, AjaxGPT on iOS, and much more!

To: US Govt, major govts, Microsoft, Apple, NVIDIA, Alphabet, Amazon, Meta, Tesla, Citi, Tencent, IBM, & 10,000+ more recipients…
From: Dr Alan D. Thompson <LifeArchitect.ai>
Sent: 31/Jan/2024
Subject: The Memo - AI that matters, as it happens, in plain English
AGI: 64%FOR IMMEDIATE RELEASE: 31/Jan/2024
Welcome back to The Memo.
You’re joining full subscribers from NVIDIA, IBM, Amazon, Microsoft, Apple, Intel, Twitter, Netflix, Google, and more…
There’s a 100% AI-generated soundtrack to this edition. The genre is close to synth-pop, the prompter used GPT-4 for the lyrics and Suno AI to generate the song from scratch (30/Jan/2024).
FatesWaltz - Ghosts in the machine:
The next roundtable will be 17/Feb/2024 (US), details at the end of this edition.
The BIG Stuff
First human Neuralink implant (28/Jan/2024)

Elon Musk: ‘The first human received an implant from Neuralink yesterday [28/Jan/2024 US time] and is recovering well. Initial results show promising neuron spike detection.’ (30/Jan/2024)
He continued: ‘The first Neuralink product is called Telepathy… Enables control of your phone or computer, and through them almost any device, just by thinking. Initial users will be those who have lost the use of their limbs. Imagine if Stephen Hawking could communicate faster than a speed typist or auctioneer. That is the goal.’ (30/Jan/2024)
Read not very much more via The Verge.
The official Neuralink study brochure (PDF) notes that ‘The study will take approximately 6 years to complete… The long-term follow-up begins immediately after completion of the Primary Study and takes place over 5 years…’
While this would possibly take us out to 2035, the shortening of timescales may mean this technology is available to the public far more quickly (recall the recent condensing of regulation and timescales in the biomedical industry, ‘Operation Warp Speed’ wiki).
Watch a short official video on Neuralink (Nov/2023): https://youtu.be/z7o39CzHgug
Read my Sep/2021 page on brain-machine interfaces, including visualization of benefits and video walk-throughs: https://lifearchitect.ai/bmi/
Exclusive: GPT-5 and gold datasets (Jan/2024)
When raising a child prodigy, should we provide more learning and experiences or higher-quality learning and experiences?
When training frontier models like GPT-5, should we use more data or higher-quality data?
In Jun/2021, I published a paper called ‘Integrated AI: Dataset quality vs quantity via bonum (GPT-4 and beyond)’. It explored high-quality data aligned with ‘the ultimate good’ (in Latin, this is ‘summum bonum’).
OpenAI’s CEO recently spoke at a number of big venues including the 54th annual meeting of the World Economic Forum (WEF) at Davos-Klosters, Switzerland from 15th to 19th January 2024. He was recorded as making a very interesting comment:
As models become smarter and better at reasoning, we need less training data. For example, no one needs to read 2000 biology textbooks; you only need a small portion of extremely high-quality data and to deeply think and chew over it. The models will work harder on thinking through a small portion of known high-quality data. (Reddit, not verbatim, 22/Jan/2024)
One researcher (22/Jan/2024) similarly notes:
…potentially 'infinity efficient' because they may be one-time costs to create. Depending on the details, you may simply create them once and then never again. For example, in ‘AlphaGeometry’, it seems likely that for most problems there’s going to be one and only one best & shortest proof, and that any search process would converge upon it quickly, and now you can just train all future geometry models on that ideal proof. Similarly, in chess or Go I expect that in the overwhelming majority of positions (even excluding the opening book & endgame databases), the best move is known and the engines aren't going to change the choice no matter how long you run them. ‘Gold datasets’ may be a good moat.
For text training, we’ve now hit massive datasets like the 125TB (30 trillion token) RedPajama-Data-v2, and I continue to track the other highlights on the Datasets Table.
Nearly three years after my data quality paper, are we finally on the way to higher quality (and perhaps temporarily smaller) datasets rather than ‘more is better’?
Explore further in my Mar/2022 comprehensive analysis of datasets, ‘What’s in my AI?’.
Exclusive: Half of all LLM innovations in January were from China (31/Jan/2024)
This month, the US was fairly quiet. In fact, only a few US-based AI labs announced new models (generally, I don’t count Llama finetunes, nor OpenAI’s minor model updates). In America, Adept announced their closed-source commercial model Fuyu-Heavy (120B), and Meta showed off their largest CodeLlama-70B model. Several of the US model innovations—like DocLLM and MambaByte—were led by researchers from China. And many of the Chinese models revealed major innovations not yet explored by US-based labs.
JPMorgan DocLLM (7B) - USA
SUTD/Independent TinyLlama (1.1B) - Singapore
Tencent LLaMA Pro (8.3B) - China
DeepSeek-AI DeepSeek (67B) - China
DeepSeek-AI DeepSeekMoE (16B) - China
Zhipu AI (Tsinghua) GLM-4 (200B) - China
Adept Fuyu-Heavy (120B) - USA
Tencent FuseLLM (7B) - China
DeepSeek-AI DeepSeek-Coder (33B) - China
Cornell MambaByte (972M) - USA
LMU MaLA-500 (10B) - Germany
RWKV RWKV-v5 Eagle (7.52B) - International
Meta AI CodeLlama-70B - USA
iFlyTek Xinghuo 3.5 (Spark) - China
iFlytekSpark-13B - China
GPT-4 cooked up a handy viz for me (30/Jan/2024) but its maths were off. So here’s the real version generated by hand in Google Charts (oh, the humanity!):

I’m not sure what China’s prolific output means, but I’m concerned that most of these models do not seem to show up in a GPT-centric world, despite many of them significantly outperforming ChatGPT. Remember, the popular gpt-3.5-turbo model is based on the GPT-3 model from 2020, available via Emerson the same year, and showcased throughout 2021 with the Leta AI experiments (watch playlist). While the internet worships this four-year-old technology (maybe the equivalent of 40 years old with the AI time multiplier), large language models are screaming along in every corner of the globe…
The Models Table: https://lifearchitect.ai/models-table/
The Interesting Stuff
China approves over 40 AI models for public use in past six months (29/Jan/2024)
China has given regulatory approval to more than 40 artificial intelligence models for public service use in the past six months, signaling a push in the country's AI sector.
Read more via Reuters.
Tencent: Viz of 44 MMLLMs (24/Jan/2024)
Beyond plain ol’ text LLMs, this paper by Tencent presents a view of MultiModal Large Language Models (MM-LLMs) including audio, embodiment, and visual language models (VLMs, models that can ‘see’ image inputs and output text). The chart begins with DeepMind Flamingo in Apr/2022, and includes recent multimodal releases like Fuyu and Gemini.

Read the paper: https://arxiv.org/abs/2401.13601
Google Lumiere (23/Jan/2024)
We introduce Lumiere, a text-to-video diffusion model designed for synthesizing videos that portray realistic, diverse and coherent motion, a pivotal challenge in video synthesis. To this end, we introduce a Space-Time U-Net architecture that generates the entire temporal duration of the video at once, through a single pass in the model…
We demonstrate state-of-the-art text-to-video generation results, and show that our design easily facilitates a wide range of content creation tasks and video editing applications, including image-to-video, video inpainting, and stylized generation.
Paper: https://arxiv.org/abs/2401.12945
Repo: https://lumiere-video.github.io/
Watch the video (link):
Samsung to integrate Baidu’s ERNIE AI in latest Galaxy phones (28/Jan/2024)
Samsung will incorporate Baidu Inc.’s ERNIE Bot into its new Galaxy S24 series in China, enhancing the phones' AI capabilities for tasks such as text summarization, organization, and translation.
Read more via Yahoo Finance.
As noted in The Memo edition 24/Jan/2024, at least in the US, ‘Samsung’s Notes, Voice Recorder and Keyboard apps will use Gemini Pro… Galaxy S24 series will also come built-in with Gemini Nano.’
Apple's Large Language Model Shows Up in New iOS Code (26/Jan/2024)
Apple is advancing its AI capabilities, with iOS 17.4 beta code indicating new Siri features powered by a large language model, including internal comparisons with OpenAI's ChatGPT for development purposes.
In total, iOS 17.4 code suggests Apple is testing four different AI models. This includes Apple's internal model called "Ajax," which Bloomberg has previously reported. iOS 17.4 shows that there are two versions of AjaxGPT, including one that is processed on-device and one that is not.
Read more via Slashdot.
Apple Vision Pro review: magic, until it’s not (30/Jan/2024)

The reviews are in already. Combining new AR-style headsets with artificial intelligence will be a huge leap for humanity.
The Apple Vision Pro is the best consumer headset anyone’s ever made — and that’s the problem.
Read more via The Verge, or a summary of reviews by AppleInsider.
Watch a video review by WSJ.
I enjoy reading Apple fanboy John Gruber’s take on these things, too (7,000 words): https://daringfireball.net/2024/01/the_vision_pro
New embedding models and API updates (25/Jan/2024)
OpenAI introduced new embedding models with improved performance and lower pricing, an updated GPT-4 Turbo, moderation models, enhanced API usage management tools, and announced upcoming reduced pricing for GPT-3.5 Turbo.
In plain English, the API now offers two new models:
New GPT-4 Turbo preview model released 25/Jan/2024: gpt-4-0125-preview
New GPT-3.5 Turbo model released 25/Jan/2024: gpt-3.5-turbo-0125
Read more via the OpenAI Blog.
OpenAI chose to drop the year from their model names, which is dangerous. I also don’t see this listed anywhere else, so I’ll write it up here with the years included:
GPT-4 original release = 14/Mar/2023
gpt-4-0314 = 14/Mar/2023
gpt-4-0613 = 13/Jun/2023
gpt-4-1106 = 6/Nov/2023
gpt-4-0125 = 25/Jan/2024
GPT-3.5-turbo original release = 30/Nov/2022 (as ChatGPT)
gpt-3.5-turbo-0301 = 1/Mar/2023
gpt-3.5-turbo-0613 = 13/Jun/2023
gpt-3.5-turbo-1106 = 6/Nov/2023
gpt-3.5-turbo-0125 = 25/Jan/2024
Sidenote to OpenAI about date formats: A friendly reminder to OpenAI to use international standards, especially ISO 8601 (wiki) which introduced the all-numeric date notation in most-to-least-significant order: YYYYMMDD. Notably, MMDD has been explicitly disallowed for the last 20 years.
Consider this example:
1st December, 2023
12th January, 2024
OpenAI is printing these dates as 1201 and 0112. When we try to sort them, 0112 will show as older, even though it is definitely newer. The cleaner format is 20231201 and 20240112. It would only cost four more characters to prevent another Y2K-like issue.
There are many reasons for following ISO 8601, including sortability, eliminating confusion between regions (especially the backwards month/date of USA vs date/month of most other regions), standardization, & general best practice. Get it together, OpenAI.
WIM: Ultra-Lightweight Wearable Mobility (Jan/2024)

This is another extended edition. Let’s look at chips beyond NVIDIA from AMD to Google, policy analysis with OpenAI’s CIA links, new models, & toys to play with…
This one is not really AI, but definitely futuristic transhumanism (wiki)!
Ultra-lightweight walking assist wearable robot, is a wearable robot that aims to promote healthy living through daily walking exercise. Walking is the most basic form of exercise that can be easily incorporated into the daily routine. Walking as an effective exercise requires proper posture, an optimal pace and a certain amount of time. WIM makes walking an easy and efficient exercise.
WIM stands for We Innovate Mobility. It feels a bit like an early version of the ‘MechWarrior’ suit concepts from the 1990s! The Korean company already has the device in production, and it is already being worn by new users in public.
Official site: https://www.wirobotics.com/en/wim.php
Watch an older video from May/2023 (link):
FuseLLM (19/Jan/2024)
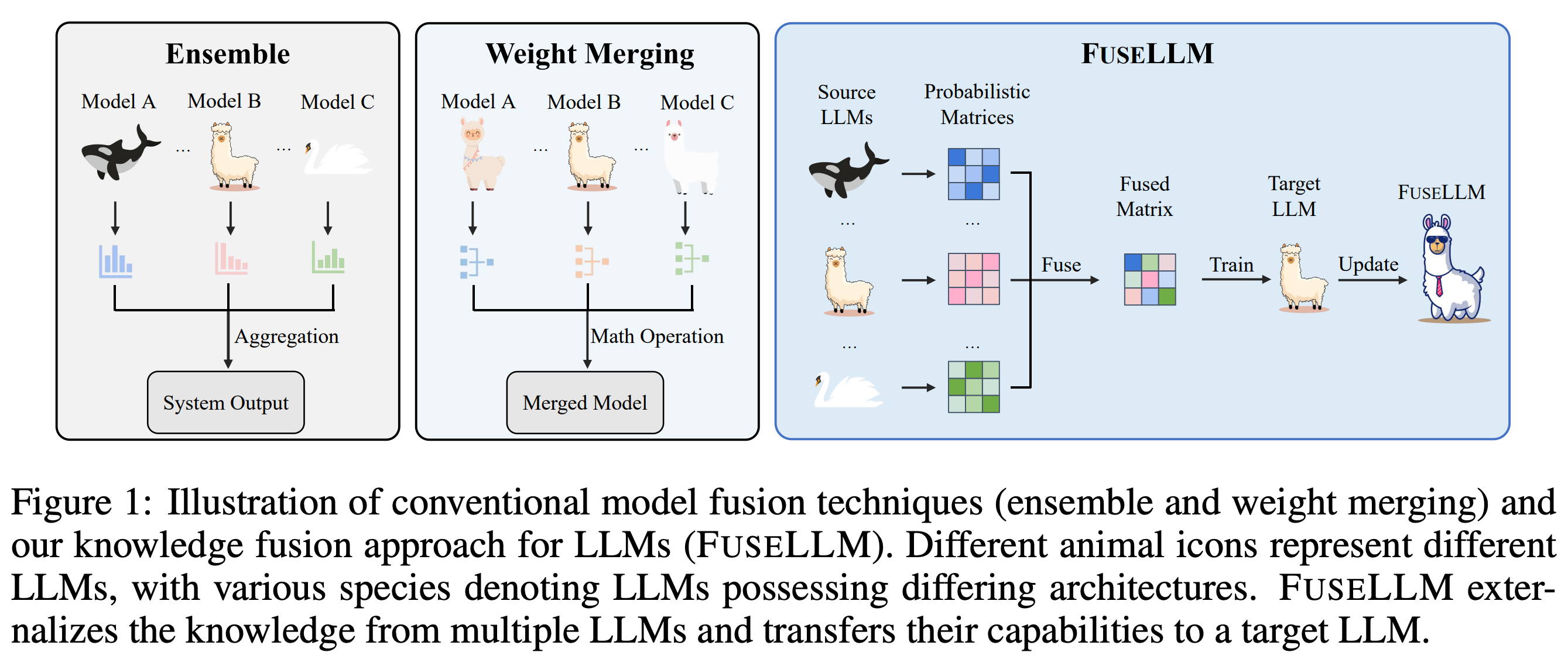
There’s a bit of complexity in this one. FuseLLM transfers knowledge and capabilities from many LLMs to a single target LLM.
Read the paper: https://arxiv.org/abs/2401.10491
View the repo: https://github.com/fanqiwan/FuseLLM
See it on the Models Table: https://lifearchitect.ai/models-table/
Leeroo orchestrator (25/Jan/2024)
Leeroo is an orchestrator that selects which LLM to use based on speed and pricing.

…when faced with a task that could be performed nearly equally well by a 7 billion parameter model or a more extensive 70 billion parameter model, the Orchestrator will opt for the former when factors like speed and cost-efficiency are prioritized. This approach ensures optimal resource utilization without compromising on quality.
Read the paper: https://arxiv.org/abs/2401.13979
See the repo: https://github.com/leeroo-ai/leeroo_orchestrator
Read the blog post.
Tesla ordering AMD MI300 (Jan/2024)
Tesla Inc. Chief Executive Officer Elon Musk said he plans to buy chips from Advanced Micro Devices Inc. as part of a spending spree on computing hardware to handle artificial intelligence.
After saying on his X social media platform that Tesla will spend more than $500 million on Nvidia Corp. hardware this year, Musk was asked if he would also buy chips from AMD. “Yes,” the billionaire replied.
Read more via Bloomberg: https://archive.md/udRnc
Google's TPU v5p AI chip could outpace Nvidia's H100 GPU (23/Dec/2023)
Google's new TPU v5p is designed to power its 'AI Hypercomputer' and is claimed to be up to 2.8 times faster at training large language models than its predecessor, potentially outperforming Nvidia's H100 GPU.
Read more via TechRadar.
Figure AI in funding talks with Microsoft, OpenAI for over US$2 billion valuation (30/Jan/2024)
Figure AI, a company developing humanlike robots, is negotiating a funding round that could reach US$500M with contributions from Microsoft and OpenAI.
Read more via Bloomberg.
Nightshade + Glaze download stats (29/Jan/2024)
We mentioned these new ‘image poisoning’ tools in The Memo edition 24/Jan/2024.
Nightshade hit 250K downloads within five days of release in Jan/2024, and they had to bring up hosting mirrors to handle the demand.
Glaze has received 2.2M downloads since it was released in April 2023.
Read more via VB.
Policy
White House science chief signals US-China co-operation on AI safety (26/Jan/2024)
In November, China signed the UK’s Bletchley Park agreement on standards for the technology, while US President Joe Biden and his Chinese counterpart Xi Jinping discussed working together on AI at a summit in California the same month.
“We are at a moment where everyone understands that AI is the most powerful technology . . . every country is bracing to use it to build a future that reflects their values,” said Prabhakar, who advises Biden on issues including AI regulation.
“But I think the one place we can all really agree is we want to have a technology base that is safe and effective,” she added. “So I think that is a good place for collaboration.”
Earlier this month, the Financial Times reported that leading US AI companies including OpenAI had engaged in covert meetings with Chinese experts to discuss the emerging risks associated with the technology.
Read more via FT.
AI companies will need to start reporting their safety tests to the US government (29/Jan/2024)
…a mandate under the Defense Production Act that AI companies share vital information with the Commerce Department, including safety tests.
Ben Buchanan, the White House special adviser on AI, said in an interview that the government wants “to know AI systems are safe before they’re released to the public — the president has been very clear that companies need to meet that bar.”…
The government’s National Institute of Standards and Technology [NIST] will develop a uniform framework for assessing safety…
The government also has scaled up the hiring of AI experts and data scientists at federal agencies.
“We know that AI has transformative effects and potential,” Buchanan said. “We’re not trying to upend the apple cart there, but we are trying to make sure the regulators are prepared to manage this technology.”
Read more via AP.
More on NIST + AI risk: https://www.nist.gov/itl/ai-risk-management-framework
More on NIST + AI safety: https://www.nist.gov/artificial-intelligence/artificial-intelligence-safety-institute
Hurd says he was ‘freaked out’ by GPT-4 briefing while on OpenAI board (30/Jan/2024)
In The Memo edition 11/Apr/2023 we explored the links between OpenAI and the CIA via board member Will Hurd. He’s recently spoken out even further.
Hurd (who has now dropped out of 2024 presidential race) expressed being ‘freaked out’ by a briefing on GPT-4 during his tenure on the board of OpenAI, stressing the need for regulatory guardrails on artificial general intelligence (AGI).
He also called for a permitting process for powerful AI systems, in which developers would apply for a permit with the National Institute for Standards and Technology (NIST) before releasing their products.
“Just like a company needs a permit to build a nuclear power plant or a parking lot, powerful AI models should need to obtain a permit too,” Hurd said. “This will ensure that powerful AI systems are operating with safe, reliable and agreed upon standards.”
Read more via The Hill.
See the conservative countdown to AGI: https://lifearchitect.ai/agi/
Toys to Play With
Agent: Open interpreter (Jan/2024)
Open Interpreter lets LLMs run code (Python, Javascript, Shell, and more) locally. You can chat with Open Interpreter through a ChatGPT-like interface in your terminal by running
$ interpreterafter installing.This provides a natural-language interface to your computer's general-purpose capabilities:
Create and edit photos, videos, PDFs, etc.
Control a Chrome browser to perform research
Plot, clean, and analyze large datasets
...etc.
Given the power of these agentic systems, I will issue a warning to please be careful with this kind of application. There are guardrails in place, but giving LLMs access to your computer’s operating system should be approached with eyes open.
Take a look: https://github.com/KillianLucas/open-interpreter
LLM App Stack by Andreessen Horowitz (a16z) (Jan/2024)
a16z has compiled a list of available tools, projects, and vendors at each layer of the LLM app stack.
Take a look: https://github.com/a16z-infra/llm-app-stack
How I used Midjourney to design a brand identity (19/May/2023)
This older article from May/2023 steps through using Midjourney to create a unique brand identity, detailing the process from defining graphic criteria to post editing for refinement.
Read more via Complete Python.
Jo’s GPT-4 SOTA bot (Jan/2024)
We had some great feedback about Jo’s prompts in the last edition of The Memo. So, here’s an unexpected output from her confidential GPT-4 bot called SOTA. Jo says: ‘Eventually, SOTA cast itself as guardian of the cosmos. It was basically a tale of its own genesis and ascent to god…’
OpenAI and Common Sense Media partner to protect teens from AI harms and misuse (29/Jan/2024)
OpenAI has teamed up with Common Sense Media to develop educational materials and guidelines for safe AI use, aimed at teens, parents, and educators, including the curation of family-friendly GPTs.
Read more via Ars.
A lifetime ago, I used to recommend Common Sense media as a tool to gauge movie suitability for my prodigy clients. Some of those resources and movies still hold up!
Setting up devices for families: https://lifearchitect.ai/devices/
Movies for prodigies: https://lifearchitect.ai/movies
Flashback
Someone recently drew my attention back to my ‘Roadmap’ paper from Jul/2022, several months before the release of ChatGPT.
…this paper provides a high-level overview of how I see the world right now, and for the next few months and years. For clarity, this is not a decades-long view; this is happening right now. Perhaps consider this report as a 48-month view from 2022 to 2026.
Read it (again): https://lifearchitect.ai/roadmap
Next
The next roundtable will be:
Life Architect - The Memo - Roundtable #7
Follows the Chatham House Rule (no recording, no outside discussion)
Saturday 17/Feb/2024 at 4PM Los Angeles
Saturday 17/Feb/2024 at 7PM New York
Sunday 18/Feb/2024 at 8AM Perth (primary/reference time zone)
or check your timezone via Google.
You don’t need to do anything for this; there’s no registration or forms to fill in, I don’t want your email, you don’t even need to turn on your camera or give your real name!
All my very best,
Alan
LifeArchitect.ai