
The Memo - Special edition: OpenAI GPT-OSS - Aug/2025
Six years after GPT-2 was released, GPT-OSS has been launched...

To: US Govt, major govts, Microsoft, Apple, NVIDIA, Alphabet, Amazon, Meta, Tesla, Citi, Tencent, IBM, & 10,000+ more recipients…
From: Dr Alan D. Thompson <LifeArchitect.ai>
Sent: 6/Aug/2025
Subject: The Memo - AI that matters, as it happens, in plain English
AGI: 94%
ASI: 0/50 (no expected movement until post-AGI)
Once again, we have this out to The Memo readers within 24 hours of announcement. (I wrote this edition while in the air…)
This is a red-letter day for open-source AI models. For the first time in six years (GPT-2 in 2019), OpenAI has released a state-of-the-art open-source model to the world. I would recommend considering running this yourself on your own laptop for most day-to-day tasks, as it offers a level of privacy and security due to not sending your data to OpenAI’s servers.
Size
The GPT-OSS reasoning models come in two sizes:
120B (116.8B) MoE, runs on an 80GB GPU or laptop, and
20B (20.9B) MoE, runs in 16GB memory or mobile device.
I expect these models were trained on >13T tokens seen (estimate, centrepoint).
OpenAI seems to confirm that the 120B model is smaller than o4-mini: ‘gpt-oss-120b and gpt-oss-20b underperform OpenAI o4-mini… This is expected, as smaller models have…’
Benchmark scores
Benchmark scores for GPT-OSS are extremely high, outperforming the ChatGPT default model.
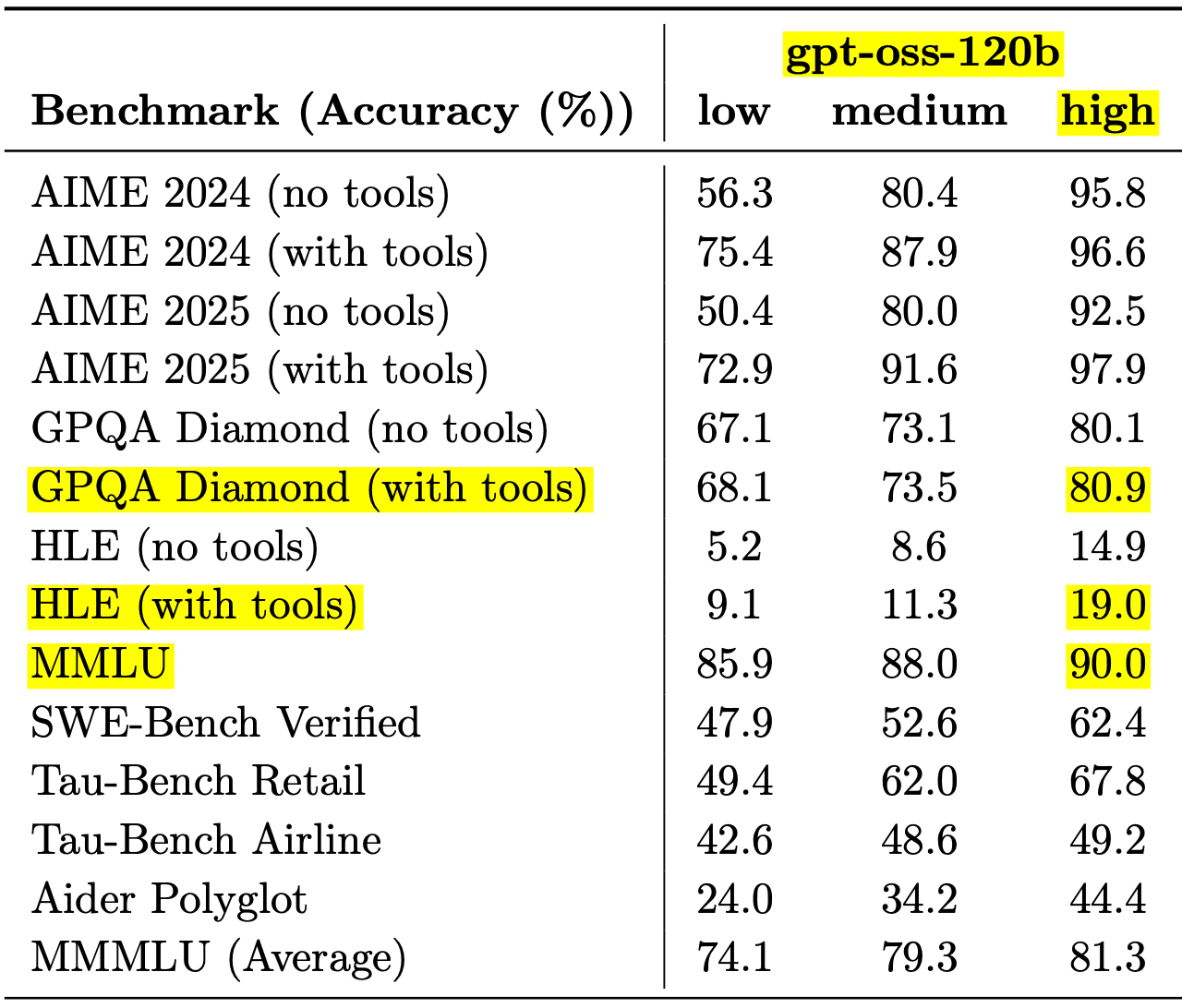
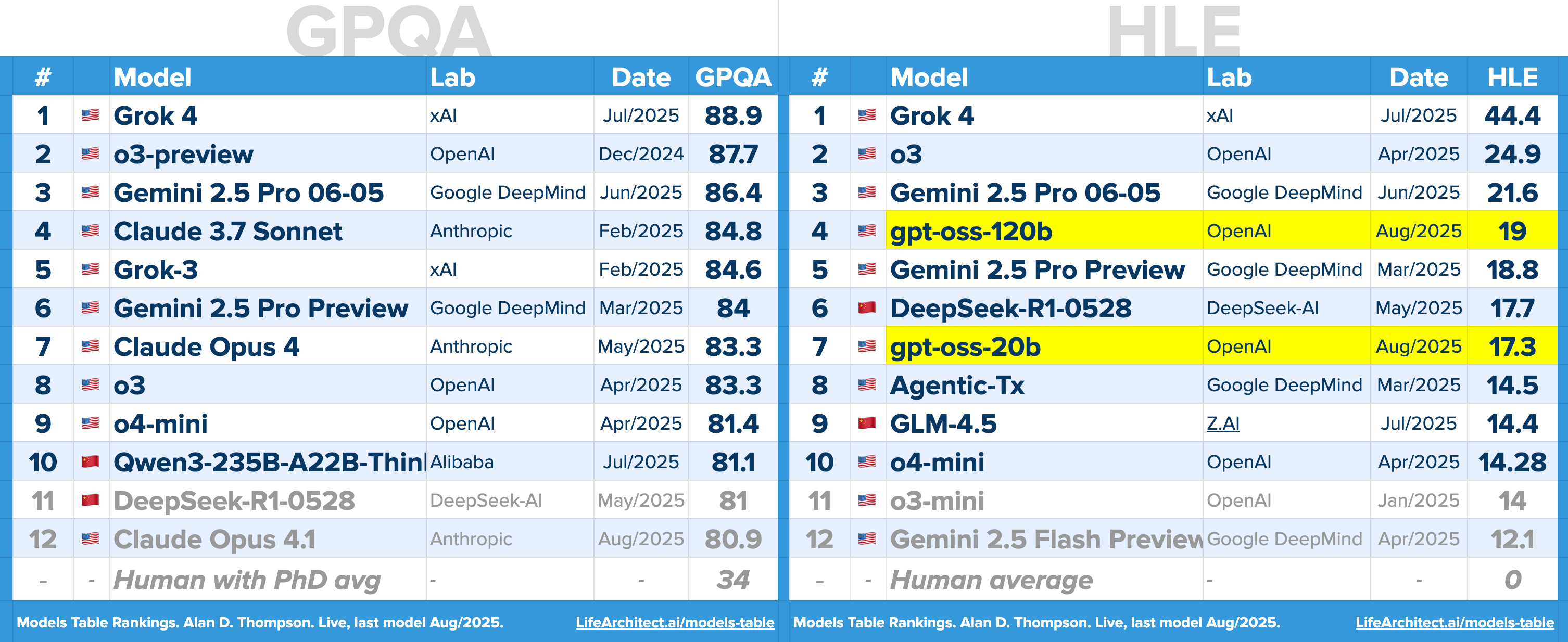
GPT-OSS-120B scored MMLU=90, GPQA=80.9, HLE=19. For comparison, ChatGPT’s initial GPT-4o model scored MMLU=88.7, GPQA=53.6. GPT-OSS is approaching (MMLU) or hitting (GPQA) the test ceilings for ‘uncontroversially correct’ answers.
Even in Spanish MMLU, gpt-oss-120B achieves MMMLU=85.9, which is exceptionally high. My testing on the ALPrompts found that gpt-oss-120B scores very poorly, averaging 0/5 for the newer prompts. It’s difficult to explain this without raising the possibility that these models have been trained on some of the main benchmark tests.
Hallucination scores are very poor, as hallucination rates are still very high. The gpt-oss-120B model scores SimpleQA hallucination=78.2% and PersonQA hallucination=49.1%. This may be the differentiator for GPT-OSS versus the upcoming GPT-5 frontier model, as I expect GPT-5 to lower hallucination rates considerably, providing closer to 100% ground truth.
Try it
Download it yourself and try it on your laptop via Jan.ai or similar: https://huggingface.co/openai/gpt-oss-120b
Try it on poe.com (official): https://poe.com/OpenAI-GPT-OSS-120B
Try it on poe.com (Together): https://poe.com/GPT-OSS-120B-T
There is an unofficial playground here: https://www.gpt-oss.com/
Documentation
Read the announce: https://openai.com/index/introducing-gpt-oss/
Read the paper (source), and I am also providing my annotated version of this paper for download:
Full subscribers can access all my annotated papers here:

Next
I expect to send another special edition within just 48 hours, as we anticipate the release of GPT-5 shortly. We’ll also cover gpt-oss and GPT-5 during the next livestream (link):
If you are thinking about becoming a full subscriber, I’d like to invite you to join in with family offices, governments, and companies from around the world.
All my very best,
Alan
LifeArchitect.ai