The Memo - 28/Feb/2026
Output of the intelligence explosion, AI outperforms human workday tasks as METR=14.5 hours, Models Table at MIT/Harvard/Stanford, and much more!

To: US Govt, major govts, Microsoft, Apple, NVIDIA, Alphabet, Amazon, Meta, Tesla, Citi, Tencent, IBM, & 10,000+ more recipients…
From: Dr Alan D. Thompson <LifeArchitect.ai>
Sent: 28/Feb/2026
Subject: The Memo - AI that matters, as it happens, in plain English
AGI: 97%
ASI: 0/50 (no expected movement until post-AGI)David Holz, founder of Midjourney (18/Feb/2026):
5 million humanoid robots working 24/7 can build Manhattan in ~6 months.
Now just imagine what the world looks like when we have 10 billion of them by 2045. Now imagine the year 2100.
Now in its sixth year, my Models Table lists all major AI model highlights since the Google Transformer, and was recently applied to a large-scale study by MIT. LifeArchitect.ai data enabled researchers to include confidential frontier model estimates and other details in their study, finding compute grew by roughly 5,000× over the study period (from Llama 2 70B to GPT-4.5), and revealing the ‘secret sauce’ advantage held by frontier AI labs. MIT paper (6/Feb/2026): https://arxiv.org/abs/2602.07238v1
In an unusual coincidence, Harvard and Stanford ran a similar study, at the same time, using the same LifeArchitect.ai data. Their conclusion reinforces the MIT finding: scale drives AI performance, and for most tasks, more compute means better results in a predictable way. (The exception is maths, where models improve faster than their compute budgets alone can explain.) Harvard/Stanford paper (17/Feb/2026): https://arxiv.org/abs/2602.15327
Contents
The BIG Stuff (Output of the intelligence explosion, METR 14.5 hours…)
The Interesting Stuff (Chinese BMIs, Figure robots 24/7…)
Policy (Anthropic vs Gov, xAI and Pentagon, distillation attacks, DeepSeek vs NVIDIA…)
Toys to Play With (g.ai, OpenAI’s mission statements, Stripe Minions, DataClaw…)
Things I’ve Been Thinking About (Responsibility for AI…)
Next (Roundtable…)
The BIG Stuff
Exclusive: LifeArchitect.ai: Output of the intelligence explosion (Feb/2026)

I’ve completed a rigorous and detailed analysis of global AI output data, both historical and projected. The chart and conclusions are confronting:
By June 2026, the total daily word output of all AI models combined is projected to exceed the total words spoken and written each day by the world’s 8.3 billion people.
By January 2027, model output from a single AI lab (likely ByteDance, Google, or OpenAI) is projected to surpass the world’s 8.3 billion people in daily spoken and written words.
Chart: https://lifearchitect.ai/intelligence-explosion.html
Background, methodology, and data: https://lifearchitect.ai/output/
I’ll be livestreaming about this in ~48 hours, click ‘notify’ to get a reminder: https://youtu.be/QZqR8Na_yB8
METR: AI now outperforming humans on standard 8-hour workday (21/Feb/2026)
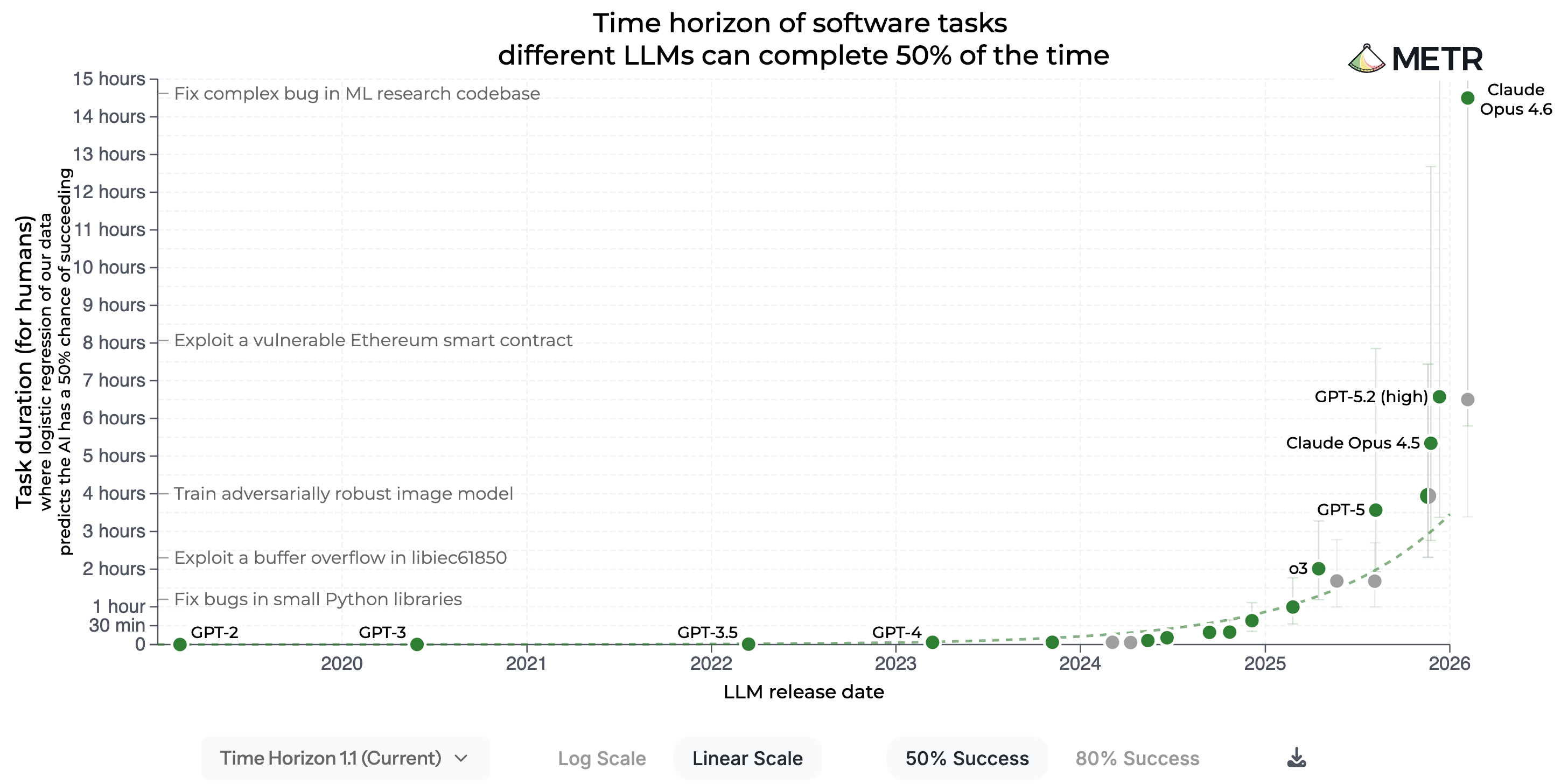
For the first time, a frontier AI model agent has exceeded an 8-hour workday task. METR estimates that Claude Opus 4.6 achieves a 50%-time-horizon of around 14.5 hours on software engineering tasks (previous record was set two months ago by GPT-5.2 at 6.5 hours), the highest point estimate they have ever reported.
In plain English, this doesn’t mean the model works for 14.5 hours straight. It means that on long, complex tasks which would take a human worker approximately 14.5 hours, the AI agent successfully completes them (while obviously finishing far faster than the human would). METR also noted their current task suite is nearly saturated, meaning frontier models are approaching the ceiling of what can be measured with existing benchmarks.
Read the announce: https://x.com/METR_Evals/status/2024923422867030027
Read more: https://metr.org/time-horizons/
I provided an explanation and examples of the METR tests in a livestream from 23/Dec/2025 (timecode): https://youtu.be/x653oFuT9Cs?t=2981
The Interesting Stuff
The Memo features in recent AI papers by Microsoft and Apple, has been discussed on Joe Rogan’s podcast, and a trusted source says it is used by top brass at the White House. Across over 100 editions, The Memo continues to be the #1 AI advisory, informing 10,000+ full subscribers including RAND, Google, and Meta AI. Full subscribers have complete access to all AI analysis items in this edition!
Google Nano Banana 2 (26/Feb/2026)