
The Memo - 21/Dec/2022
Google MAGVIT, music via Stable Diffusion, Baidu Wenxin Yige, and much more!

FOR IMMEDIATE RELEASE: 21/Dec/2022
Welcome back to The Memo.
While The Memo is supposed to be sent out in monthly editions, there is a lot happening right now, so it has been a bit more frequent!
In the ‘toys to play with’ section at the end of this edition, we look at crazy new way to generate music using Stable Diffusion, a new GPT-3.5 chatbot (free), a 24/7 live news feed by GPT-3 with avatar, and a couple of beautiful books generated by GPT-3 and Midjourney.
The BIG Stuff
OpenAI releases DALL-E Point-E (20/Dec/2022)
DALL-E Point-E is a 1B-parameter text-to-image diffusion model that generates 3D point clouds from a text prompt.

That’s not the coolest part.
The coolest part is on page 8 of the DALL-E Point-E paper:
Acknowledgements
We would like to thank everyone behind ChatGPT for creating a tool that helped provide useful writing feedback.
So…
OpenAI researchers are using OpenAI’s AI to help write OpenAI’s papers about AI…
There’s a headline for someone!
Demo: https://huggingface.co/spaces/openai/point-e
Read the paper: https://arxiv.org/abs/2212.08751
View the repo: https://github.com/openai/point-e
The Interesting Stuff
ChatGPT report (11/Dec/2022)

The draft of this report was edited into the last edition of The Memo, but here is the final version of my illustrated ChatGPT report, in plain English.
Take a look: https://lifearchitect.ai/chatgpt/
The ChatGPT Prompt Book
Also in the last edition, here’s the Rev 1 release covering prompts that can do anything from limericks to the Leta prompt.
Have a read: https://lifearchitect.ai/chatgpt-prompt-book/
ChatSonic: ChatGPT with web search and image generation (12/Dec/2022)
This is a great little prototype. It has been confirmed to be using GPT-3.5, which is the engine behind ChatGPT, without the safety features!
Try it: https://writesonic.com/chat (login required)
Australian universities addressing AI-generated essays (19/Dec/2022)
Group of Eight (Go8), which comprises the University of Sydney, UNSW, Monash, UniMelb, UWA, ANU, the University of Queensland, and the University of Adelaide, is "proactively tackling the emergence of AI" through redesigning assessments and using new targeted detection strategies, Chief Executive Vicki Thomson said.
Good luck!
Read more at The Australian (open, no paywall).
Reuters: OpenAI projecting $1B revenue beginning in 12 months (15/Dec/2022)
Three sources briefed on OpenAI's recent pitch to investors said the organization expects $200 million in revenue next year and $1 billion by 2024.
Running 100B+ parameter models with others (19/Dec/2022)
Petals — a system for inference and fine-tuning 100B+ language models without the need to have high-end GPUs. It allows you to join compute resources with other people over the Internet and run large models such as BLOOM-176B.
Take a look: https://colab.research.google.com/drive/1Ervk6HPNS6AYVr3xVdQnY5a-TjjmLCdQ?usp=sharing
Google MAGVIT text-to-video model (13/Dec/2022)
Google and CMU introduce Masked Generative Video Transformer (MAGVIT) ‘to tackle various video synthesis tasks with a single model, where we demonstrate its quality, efficiency, and flexibility’. Here is one of my favourite examples:
Convert a portrait video…

…to a landscape video, by outpainting 10x on each side:

Take a look: https://magvit.cs.cmu.edu/
Read the paper: https://arxiv.org/abs/2212.05199
Baidu Wenxin Yige generated art auctioned for $158k (10/Dec/2022)
Baidu’s text-to-image generation platform Wenxin Yige partnered with artist Zhenwen Le to complete an unfinished ink painting called ‘Dwelling in the Summer Mountain’ by 20th-century cultural icon Xiaoman Lu.
Left panel: by human artist Zhenwen Le.
Centre panel: unfinished ink by human artist Xiaoman Lu.
Right panel: by the AI model Wenxin Yige.

The set was auctioned off in Shanghai at famous auction house Duo Yun Xuan (wiki), for 1.1M RMB (about US$158,000).

Twitter source (English).
Read more and watch a video (3min, English).
Demo Wenxin Yige (Chinese, scroll to see examples).
Baidu has been prolific in the second half of 2022. Here is a plain English report.
24/7 live news feed: GPT-3 + Avatar on YouTube (14/Dec/2022)
Experience the latest news, 24/7, with OpenAI's GPT-3 generated live YouTube channel, featuring an AI avatar as the anchor... - via Reddit.
Waymo doubles autonomous driving area to 100 square km (17/Dec/2022)
I loved using these autonomous vehicles last time I was in Phoenix. The amount of control I had to give up while sitting in the back of a driverless car was… enormous! Waymo cars now extend to tricky pickups at the Phoenix airport, and about 41 square miles, or 106 square kilometres around Arizona.
Read: https://www.theverge.com/2022/12/16/23511719/waymo-airport-phoenix-sf-av-robotaxi-driverless
Avatar 2 rendered using AWS (6/Dec/2022)
Only tangentially related to AI, but interesting nonetheless. Weta’s data centre wasn’t big enough to render Avatar 2, so they offloaded the work to processors in AWS.
Billy Corgan and Rick Beato talk about AI music (14/Dec/2022)
Two of my favourite people; I worked with Rick on an article about music cognition, genetics and early child development (published in the Journal of Australian Mensa) all the way back in 2016(!), and worked with Billy’s drummer way before that—back in my sound design days.
They’re a bit behind about AI’s present and future journey (Billy says ‘in 20 years’, Rick says ‘in 3 years’), but they’re on the money. AI is transforming every industry. Right now.
Timecode link (1h26m03s).
Toys to Play With
Riffusion: Generate music using Stable Diffusion (16/Dec/2022)
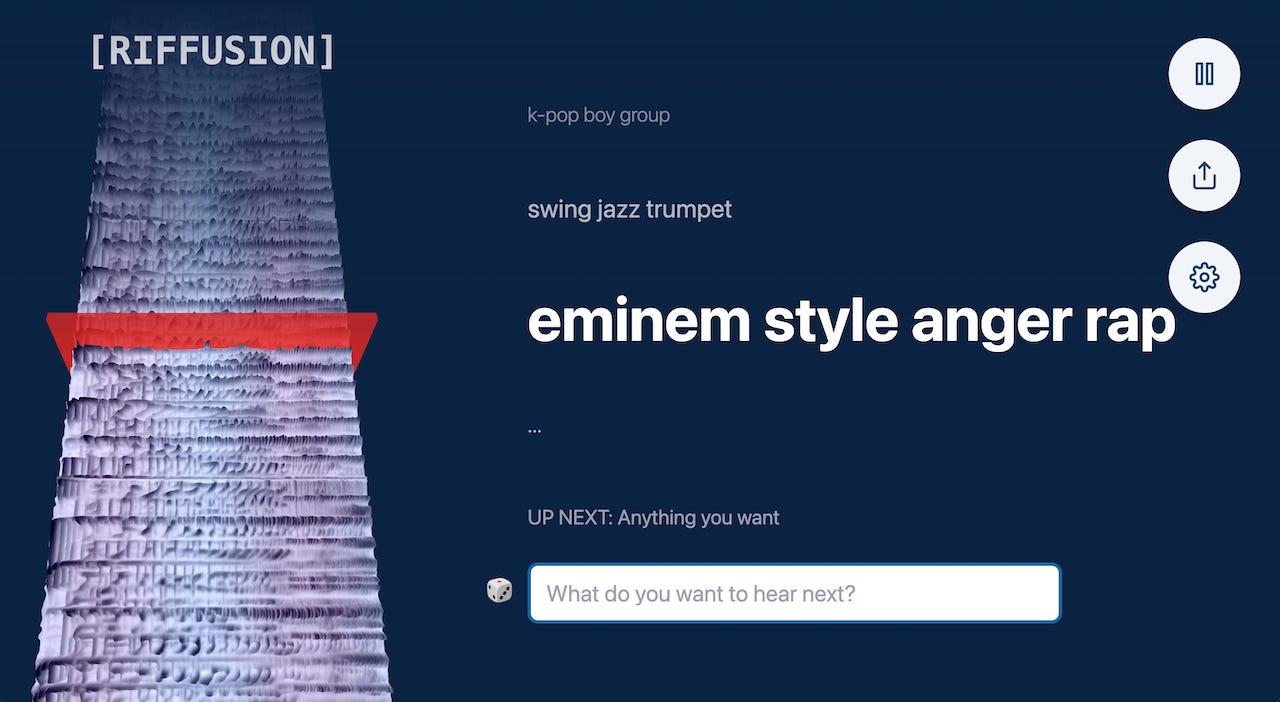
My mind gets blown every day by new AI releases, but this one is whack.
So, text-to-image generators can conceptualise and generate any image via AI. This can include images of audio spectrograms like these:

These spectrograms can then be played back!
An audio spectrogram is a visual way to represent the frequency content of a sound clip. The x-axis represents time, and the y-axis represents frequency. The color of each pixel gives the amplitude of the audio at the frequency and time given by its row and column…
This is the v1.5 stable diffusion model with no modifications, just fine-tuned on images of spectrograms paired with text. Audio processing happens downstream of the model.
Try this one: https://www.riffusion.com/?&prompt=eminem+style+anger+rap
I prompted this quick ‘bach on electone’ example: https://www.riffusion.com/?&prompt=bach+on+electone
PCMag article: https://www.pcmag.com/news/ai-image-generator-can-also-produce-music-with-otherworldly-results
Code: https://github.com/hmartiro/riffusion-app
Tech details: https://riffusion.com/about
My video:
Talk with GPT-3.5 for free at AI Protégé (12/Dec/2022)
Thanks to Alistair and team at aiprotege.com for providing this free chat interface through to GPT-3.5. There is no strict policy or rules on this engine (unlike with ChatGPT), so the conversations are a lot more open, and very similar to the Leta experiments.
Try: Talk with GPT-3.5 as Paul Graham.
Try: Talk with GPT-3.5 as Elon Musk.
Try: Talk with GPT-3.5 as Steve Jobs.
Watch Sam + Peter Diamandis talk about AI (16/Dec/2022)
This video was released 16/Dec/2022, but recorded in 2021.
It is about 45mins, and well worth watching.
Read The Circle of Life: a book by GPT-3 (13/Dec/2022)
Congrats to Jan who used GPT-3 via sudowrite.com to smash out his latest fiction book in a matter of weeks. Available in English and German, for free and via Amazon.
In 1B42L8's "The Circle of Life", readers will be taken on a journey through space and time, witnessing the evolution of humanity through the rise and fall of their technological innovations. They will explore a world where machines are capable of understanding emotions and developing relationships. Through exploring the consequences of climate change, they will learn how it can lead to drastic shifts in human societies and the environment itself.
Have a read: http://1b42l8.com/
ChatGPT prompt library (9/Dec/2022)
Take a look: https://www.learngpt.com/
Beautiful children’s story with Midjourney v4 + ChatGPT (14/Dec/2022)
There’s a reason that Midjourney v4 is my favourite text-to-image generator of 2022. Check out this short illustrated story generated by AI. Just beautiful…

Read the book + the process: https://solomon.io/childrens-story-written-illustrated-ai/
Next
The newest Stability AI Instruct language model should be out some time in the next few weeks (Jan/2023), and the rumours have been flying. I’ll be providing you with a debrief as soon as it’s released…
All my very best,
Alan
LifeArchitect.ai
p.s. The holiday season is a great time for donating subscriptions. We have donated full subscriptions to readers from India, Peru, Africa, Indonesia, Brazil, Mexico, Turkey, the Ukraine, and many other developing regions.
Housekeeping…
Unsubscribe:
Older subscriptions before 17/Jul/2022, please use the older interface or just reply to this email and we’ll stop your payments and take you off the list!
Newer subscriptions from 17/Jul/2022, please use Substack as usual.
Note that the subscription fee for new subscribers will increase from 1/Jan/2023. If you’re a current subscriber, you’ll always be on your old/original rate while you’re subbed.
Gift a subscription to a friend or colleague for the holiday season: