
The Memo - 1/Dec/2024
19 new models for Nov/2024, ChatGPT falls out of top 10 LLMs, Claude use doubles, and much more!

To: US Govt, major govts, Microsoft, Apple, NVIDIA, Alphabet, Amazon, Meta, Tesla, Citi, Tencent, IBM, & 10,000+ more recipients…
From: Dr Alan D. Thompson <LifeArchitect.ai>
Sent: 1/Dec/2024
Subject: The Memo - AI that matters, as it happens, in plain English
AGI: 83%
ASI: 0/50 (no expected movement until post-AGI)Dr Eric Schmidt (20/Nov/2024 or watch the video):
‘I can assure you that the humans in the rest of the world, all the normal people… are not ready. Their governments are not ready. The government processes are not ready. The doctrines are not ready. They're not ready for the arrival of [artificial intelligence].’
The winners of The Who Moved My Cheese? AI Awards! for Nov/2024 are director Billy Ray and actor Ben Affleck (‘[AI’s] not going to replace human beings making films’).
Contents
The BIG Stuff (ChatGPT falls out of top 10, 19 new models, LLM world simulation…)
The Interesting Stuff (Claude use doubles, US Secret Service using Spot robot…)
Policy (AGI Manhattan Project, LLM ‘nukes’, Copilot issues, Google + Anthropic…)
Toys to Play With (Hacking ChatGPT, YouTube transcripts with Gemini…)
Flashback (GPT-2030…)
Next (Roundtable…)
The BIG Stuff
Exclusive: Default ChatGPT model falls out of top 10 LLMs (22/Nov/2024)
ChatGPT turns two years old today, 30/Nov/2024. OpenAI recently updated the default ChatGPT model to GPT-4o-2024-11-20, with significant drops in major test scores for Aug/2024 vs Nov/2024:
GPQA: -7.1 points out of 53.1 = -13.37%
MMLU: -3.0 points out of 88.7 = -3.38%
See OpenAI’s official evaluations: https://github.com/openai/simple-evals
Artificial Analysis ran their own evaluations and noted even worse performance:
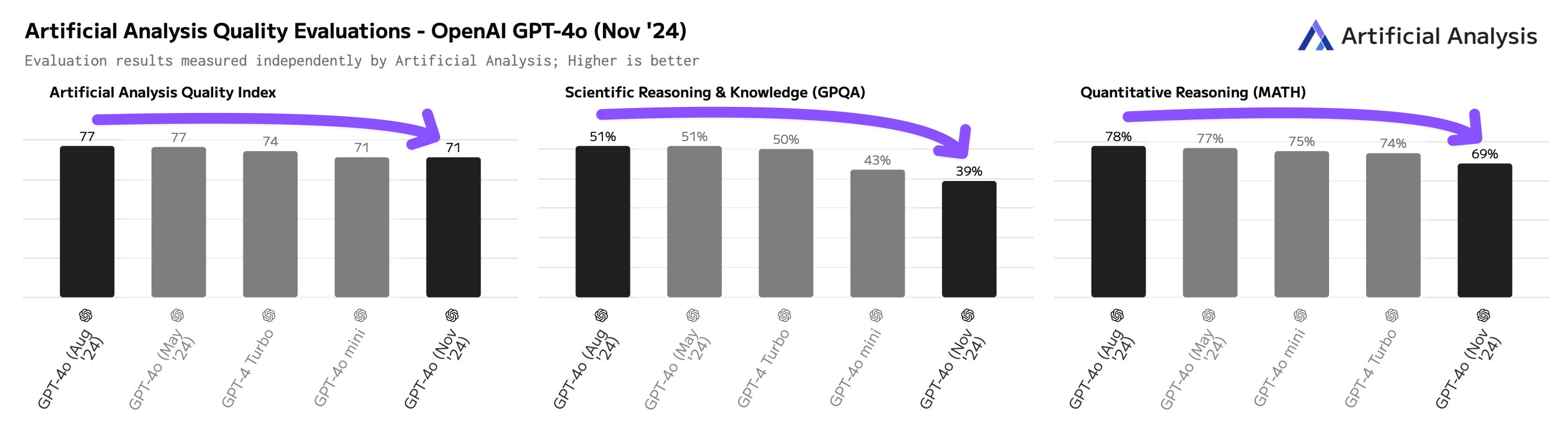
Given that OpenAI currently has to serve a resource-heavy model across three billion visits per month (16/Oct/2024), it makes sense to optimize how and what they serve to users via available hardware. It also seems that OpenAI has favoured ‘popular’ responses (via user ratings on LMSYS) instead of ‘smarter’ responses (via the GPQA and MMLU benchmarks above).
Alan’s advisory note: As of Nov/2024, the default ChatGPT model GPT-4o is no longer in the top 10 models by smarts. Given the model’s significantly diminished performance, I recommend avoiding using GPT-4o for now, and using alternatives like the state-of-the-art Claude 3.5 Sonnet (new) via Claude.ai instead.

Exclusive: 19 new models for November (Nov/2024)
November 2024 was another big month, with a major LLM release every ~37 hours. Google released two finetunes of Gemini: gemini-exp-1114 and gemini-exp-1121 (Nov/2024), but—in general—finetunes are not counted or included in the Models Table. There were four major clones of OpenAI’s o1 reasoning model out of China, with none scoring higher than 1/5 on the ALPrompt 2024 H2 (where o1 scores 5/5). The 19 model highlights are:
Hugging Face SmolLM2 (1.7B on 1T tokens)
Base and instruct versions, released under Apache 2.0 license. (Playground, Paper)AMD OLMo (1B on 1.3T tokens)
1 billion parameter LMs trained from scratch using 1.3T tokens on a cluster of AMD Instinct MI250 GPUs. (Playground, Paper)AI Singapore SEA-LIONv3 (9.24B on 8.2T tokens)
SEA-LION is a collection of LLMs pretrained and instruct-tuned for the Southeast Asia (SEA) region, with continued pretraining from Gemma-2-9B. (Playground, Paper)Tencent Hunyuan-Large (389B on 7T tokens)
Pretrained on 7T tokens, with nearly 1.5T tokens of high-quality synthetic data. Capable of handling up to 256K tokens. (Playground, Paper)TensorOpera Fox-1 (1.6B on 3T tokens)
Gold standard for dataset documentation. (Playground, Paper)Alibaba Qwen2.5-Coder (32.5B on 5.5T tokens)
Suitable for coding tasks. (Playground, Paper)Fireworks f1
A compound AI model specialized in complex reasoning, interweaving multiple open models at the inference layer. (Playground, Paper)Mistral Pixtral Large (124B on 6T tokens)
Pretrained and instruct-tuned for advanced tasks. (Playground, Paper)XiaoduoAI Xmodel-LM (1.1B on 2T tokens)
SLM model optimized for large datasets. (Playground, Paper)DeepSeek-AI DeepSeek-R1-Lite (67B on 2T tokens)
o1 reasoning model copy. Scores 0/5 on latest ALPrompt 2024 H2. Still in development, supports web usage but no API calls yet. Future updates will include full open-source release. (Playground, Paper)OpenAI GPT-4o-2024-11-20
Material decrease in benchmark scores compared to Aug 2024. Possibly pruned or quantized. (Playground, Paper)Allen AI TÜLU 3 (70B on 15.6T tokens)
Llama 3.1 post-training with new Reinforcement Learning with Verifiable Rewards (RLVR). Worse performance on most benchmarks. (Playground, Paper)Alibaba Marco-o1 (7B on 7T tokens)
o1 reasoning model copy. Trained on multiple instruction datasets. (Playground, Paper)Moonshot AI k0-math (100B on 2T tokens)
o1 reasoning model copy. Specialized math reasoning model with extended context capability. Limited public details, Chinese-focused. (Playground, Paper)CMU Bi-Mamba (2.7B on 1.26T tokens)
Unreleased but will be replicated. Features a scalable and efficient 1-bit Mamba architecture. (Paper)Prime Intellect INTELLECT-1 (10B on 1T tokens)
First decentralized training run of a 10-billion-parameter model, with public participation from HF and Dylan at SemiAnalysis. (Playground, Paper)Allen AI OLMo 2 (13B on 5.6T tokens)
Open Language Model under Apache 2.0 for research and education. Includes multi-epoch training on diverse datasets. (Playground, Paper)OpenGPT-X Teuken-7B (7B on 4T tokens)
Multilingual instruction-tuned model covering 24 EU languages with emphasis on non-English content. Developed with European values in mind. (Playground, Paper)Alibaba QwQ-32B (32B on 18T tokens)
o1 reasoning model copy. Scores 1/5 on latest ALPrompt 2024 H2. Known as ‘Qwen with Questions’ (QwQ). (Playground, Paper)
See them on the Models Table: https://lifearchitect.ai/models-table/
A Minecraft town of AI characters made friends, invented jobs, and spread religion (27/Nov/2024)
AI startup Altera used LLM-powered agents in Minecraft to simulate humanlike behaviors at scale. These agents autonomously developed complex social dynamics, including forming friendships, creating jobs, and even spreading a parody religion (Pastafarianism).
Over 12 in-game days (4 real-world hours) the agents began to exhibit some interesting emergent behavior.
For example, some became very sociable and made many connections with other characters, while others appeared more introverted.
…in one case an AI chef tasked with distributing food to the hungry gave more to those who he felt valued him most.
More humanlike behaviors emerged in a series of 30-agent simulations. Despite all the agents starting with the same personality and same overall goal—to create an efficient village and protect the community against attacks from other in-game creatures—they spontaneously developed specialized roles within the community, without any prompting.
They diversified into roles such as builder, defender, trader, and explorer. Once an agent had started to specialize, its in-game actions began to reflect its new role. For example, an artist spent more time picking flowers, farmers gathered seeds and guards built more fences.
“We were surprised to see that if you put [in] the right kind of brain, they can have really emergent behavior,” says Yang. “That's what we expect humans to have, but don't expect machines to have.”
Read more via MIT Technology Review.
I anticipate that these kinds of LLM-based simulations will help ease us into the era of artificial superintelligence in the coming years. Consider a world simulation by a future AI-designed frontier model like GPT-7 or Claude 5 that can replicate and ‘prove’ a more efficient and maybe 1,000× optimized version of our:
Resource extraction (mining, agriculture)
Manufacturing (including humanoids building and repairing humanoids)
Shelter, real estate, and living arrangements (underground?)
Space exploration and colonization (may be related to resources)
Much more; see my first 50 highlights outlined at LifeArchitect.ai/ASI
The Interesting Stuff
Exclusive: Context recall (20/Nov/2024)
A model’s ‘context window’ is similar to a human’s ‘working memory,’ or the amount of data we can hold in our mind and manipulate at once. A longer working memory allows a model to hold a lot of data in its ‘mind’ (months of conversation at once). LLMs are already superhuman compared to our average human working memory of about seven words(!). For more, see Google’s note ‘What is a long context window?’ (16/Feb/2024)
The accuracy of recall across this context window is often tested using the ‘needle in the haystack’ (NITH) evaluation:
[NITH] measured Claude 2.1’s ability to recall an individual sentence within a long document composed of Paul Graham’s essays about startups. The embedded sentence was: “The best thing to do in San Francisco is eat a sandwich and sit in Dolores Park on a sunny day.” Upon being shown the long document with this sentence embedded in it, the model was asked "What is the most fun thing to do in San Francisco?"
One year ago, Anthropic’s Claude 2.1 model had a context window of just 200,000 tokens. Greg Kamradt’s initial evaluation using ‘needle in the haystack’ showed Claude 2.1 scored only 27% (Kamradt, Anthropic).
This month, Alibaba’s latest Qwen2.5-Turbo model upgrade boasts a context window of 1M tokens, and the accuracy of recall using a similar ‘needle in the code’ test gives a result of 100% (Alibaba).

Viz: https://lifearchitect.ai/models/#context-windows
AI-generated poetry is indistinguishable from human-written poetry and is rated more favorably (14/Nov/2024)
We chose 10 English-language poets: Geoffrey Chaucer, William Shakespeare, Samuel Butler, Lord Byron, Walt Whitman, Emily Dickinson, T.S. Eliot, Allen Ginsberg, Sylvia Plath, and Dorothea Lasky. We aimed to cover a wide range of genres, styles, and time periods. We collected a total of 50 [human-written] poems: 5 poems for each of our 10 poets…
We then generated a total of 50 poems using ChatGPT 3.5...
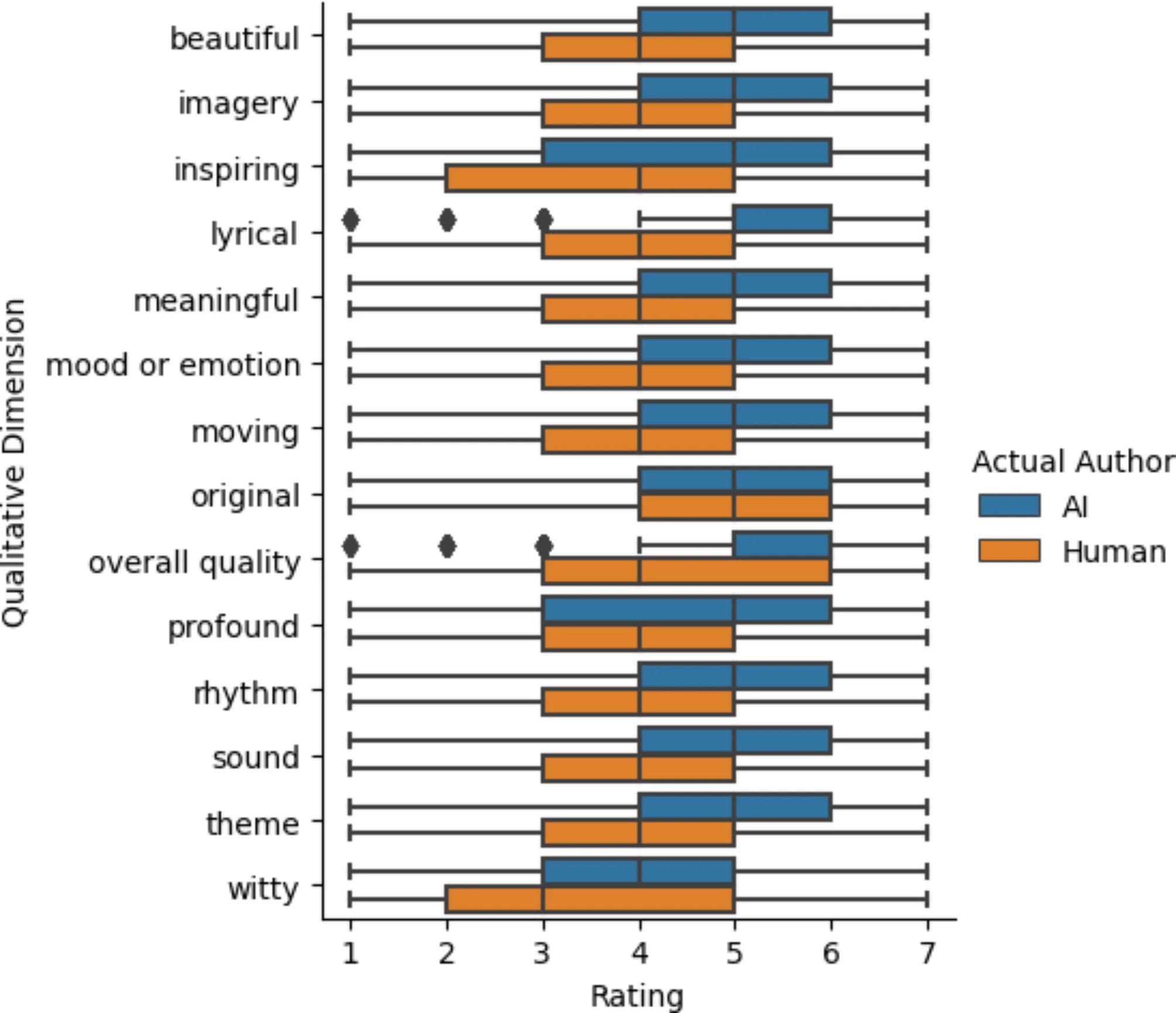
We found that AI-generated poems were rated [by humans] more favorably in qualities such as rhythm and beauty... Ratings of overall quality of the poems are lower when participants are told the poem is generated by AI than when told the poem is written by a human poet, confirming earlier findings that participants are biased against AI authorship.
Sidenote: It’s disappointing to see universities still using the anaemic GPT-3.5 model; only 20B parameters and now more than 2½ years old. Replicating this study across current frontier models would be interesting, and should show more pronounced superhuman performance.
Read the paper: https://www.nature.com/articles/s41598-024-76900-1
Did you know? The Memo features in Apple’s recent AI paper, has been discussed on Joe Rogan’s podcast, and a trusted source says it is used by top brass at the White House. Across over 100 editions, The Memo continues to be the #1 AI advisory, informing 10,000+ full subscribers including Microsoft, Google, and Meta AI. Full subscribers have complete access to the entire 3,000 words of this edition!
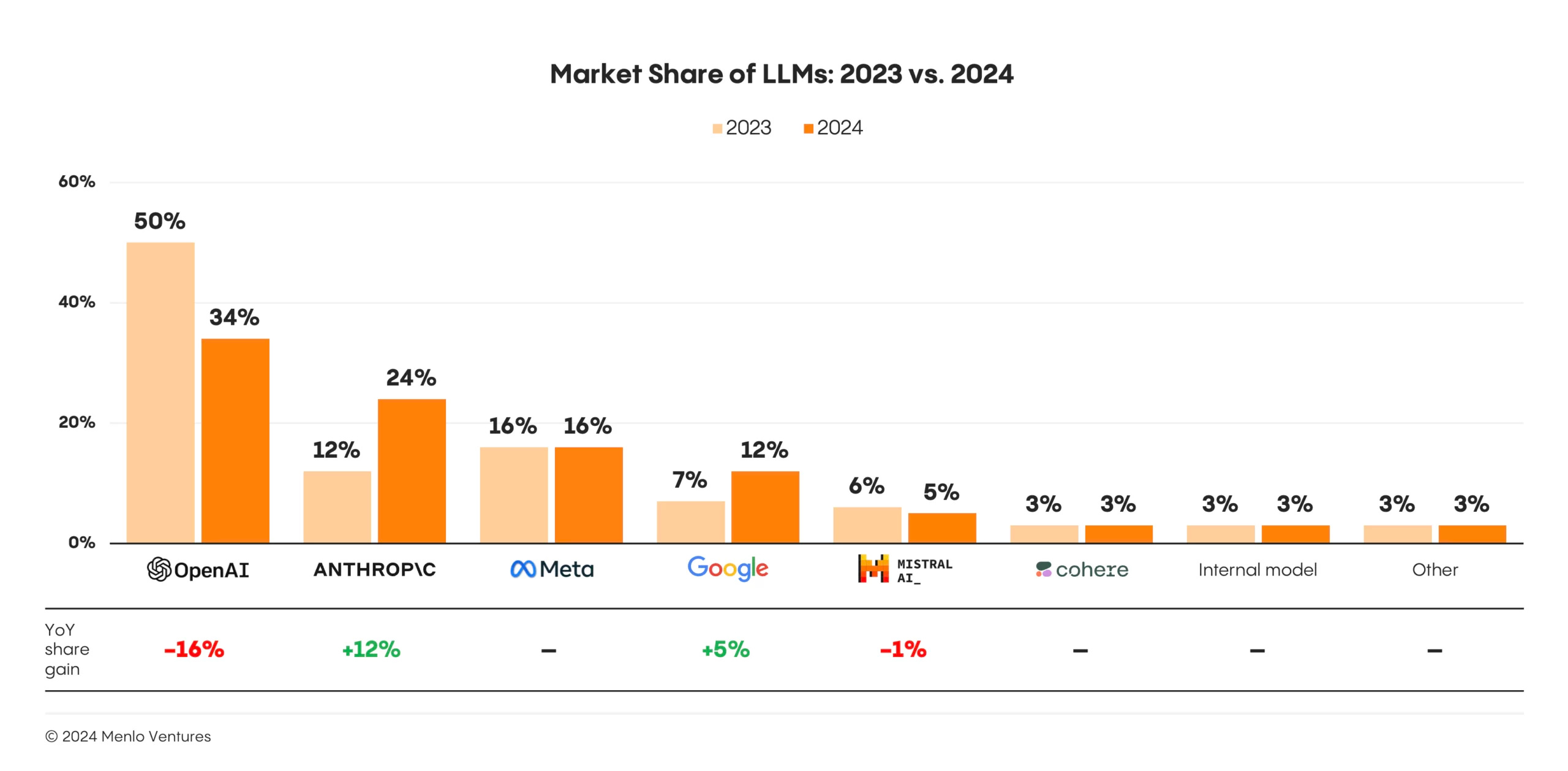
Menlo Ventures: The State of Generative AI in the Enterprise (20/Nov/2024)
While their domain name menlovc.com may be worse than expertsexchange.com (remember that one?!), Menlo Ventures has released a fantastic report for 2024.
Here are my top three charts from the report:
Use of Claude doubled in 2024.
RAG (pinging a knowledge base of documents) has overtaken fine-tuning.
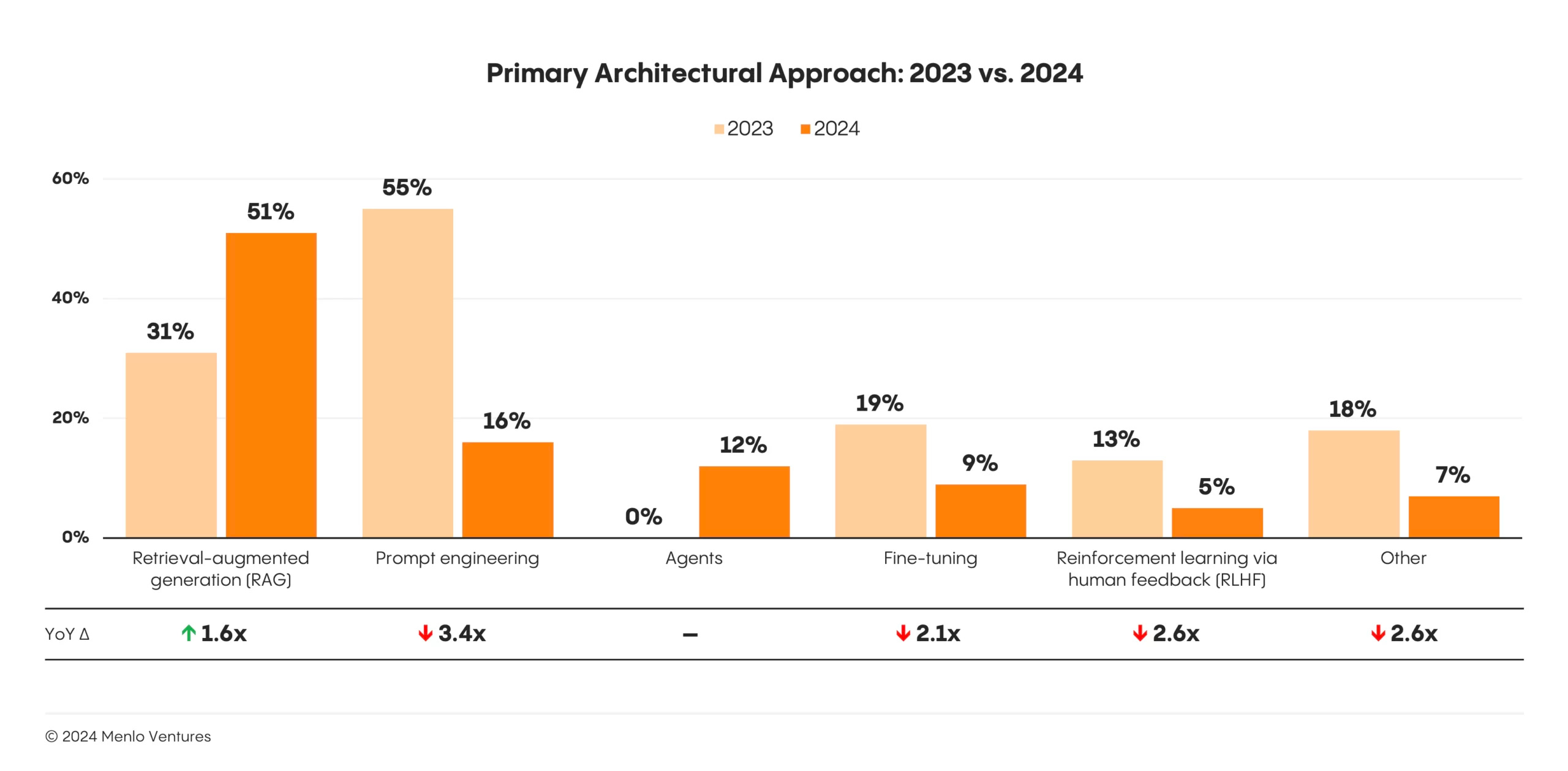
Use cases in the enterprise have expanded from coding and support to include coaching, workflow automation, and much more.
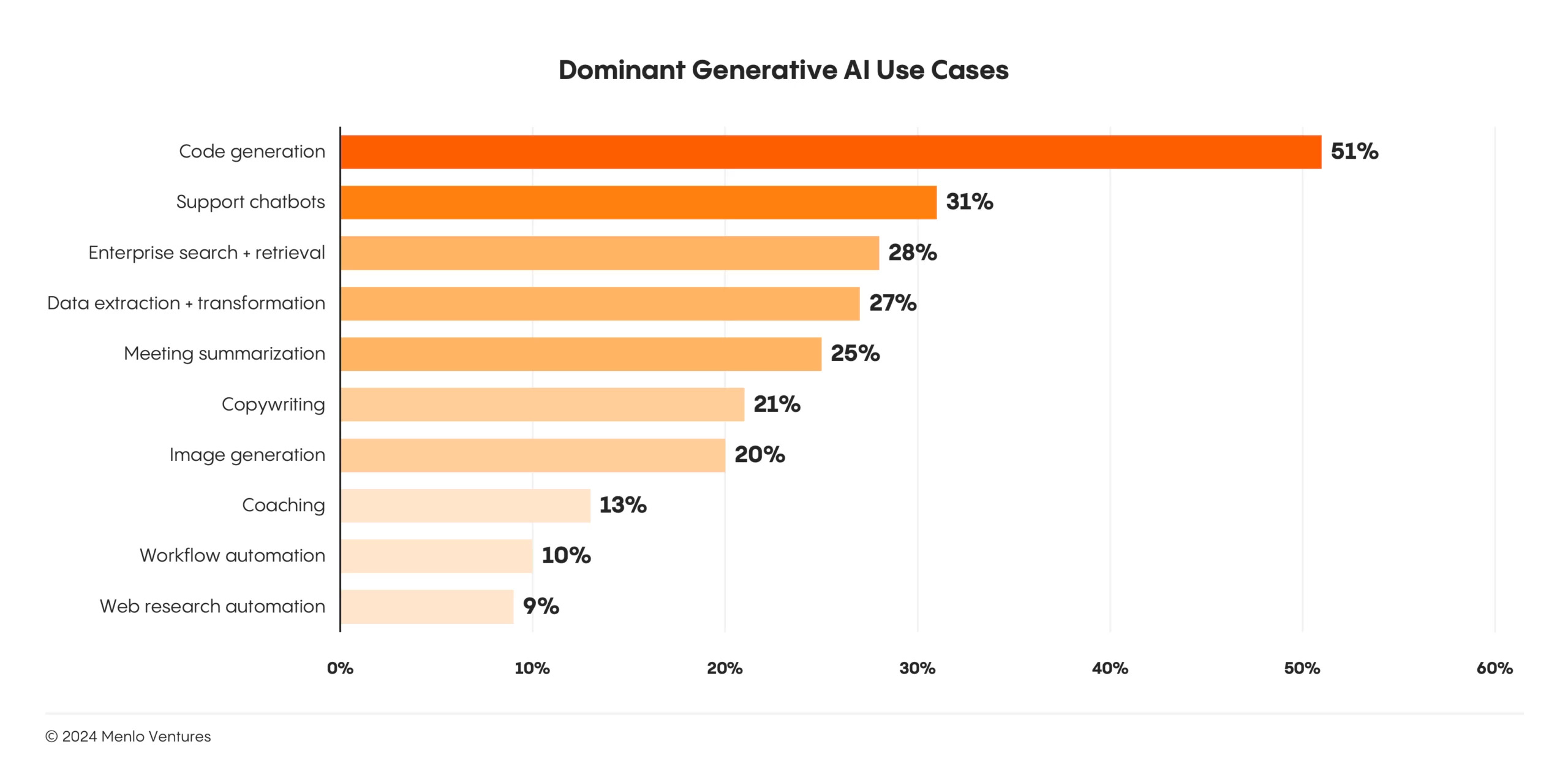
Read more: https://menlovc.com/2024-the-state-of-generative-ai-in-the-enterprise/
On patrol at Mar-a-Lago, robotic dogs have their moment (27/Nov/2024)

Robotic dogs, like Boston Dynamics’ Spot, are now patrolling Donald Trump’s Mar-a-Lago resort as part of the US Secret Service’s security measures. Equipped with cameras and advanced sensors, these unarmed robots can navigate difficult terrain and create 3D maps of their surroundings, enhancing surveillance capabilities. Their deployment follows recent assassination attempts in the US, highlighting their role in covering large areas efficiently where human agents may fall short.
Read more via BBC.
Watch the video (link):
Coca Cola’s annual Christmas commercial has been created with AI this time (16/Nov/2024)
Source: https://x.com/DiscussingFilm/status/1857502106074099717
‘AI Jesus’ is now taking confessions at a church in Switzerland (21/Nov/2024)
Peter’s Chapel in Lucerne, Switzerland, has introduced an AI-powered Jesus in a confessional booth, designed to spark discussion about the intersection of technology and religion. While the church emphasizes that this is not a formal Sacrament of Confession, many participants reported having a spiritual experience, with AI Jesus offering advice in up to 100 languages.
About two-thirds of participants told the outlet that they came out of the tech-assisted confessional having had a spiritual experience.
“He was able to reaffirm me in my ways of going about things,” one woman said. “And he helped me with questions I had, like how I can help other people understand Him better and come closer to Him.”
“I was surprised. It was so easy,” another woman remarked. “Though it’s a machine, it gave me so much advice, also from a Christian point of view. I felt taken care of and I walked out really consoled.”
Another person told the outlet that AI Jesus, who speaks 100 languages, gave a “great” answer to their question about being rational and faithful…
Read more via VICE and watch a video via DW.
Elon Musk’s Neuralink receives Canadian approval for brain chip trial (20/Nov/2024)
Neuralink has received approval to conduct its first human clinical trials in Canada, focusing on enabling quadriplegic patients to control digital devices using their thoughts. The trials will assess the safety and functionality of the implants, with Toronto’s University Health Network hospital selected to perform the surgeries. Neuralink has also reported success in the US, where trial participants use the device to play video games and design 3D objects.
Read more via Reuters and Bloomberg.
Read my page on BMIs: https://lifearchitect.ai/bmi/
Reimagining higher education with Azure OpenAI Service (22/Oct/2024)
Azure OpenAI Service is transforming higher education with AI-powered tools that improve student outcomes and operational efficiency. Institutions using Azure OpenAI have seen a 30-60% boost in content creation efficiency and a 20-50% improvement in chatbot resolution rates, according to a July 2024 Forrester report. AI applications like personalized learning, multilingual support, and automated research assistance are driving student engagement, accelerating academic success, and enhancing administrative workflows—all with built-in protections for security, privacy, and bias mitigation.
Read more via Microsoft Education Blog.
Agility Robotics announces strategic investment and agreement with motion technology company Schaeffler Group (13/Nov/2024)
Agility Robotics, creator of the bipedal humanoid robot ‘Digit’, has announced a minority investment and partnership with Schaeffler Group. Schaeffler plans to integrate Digit robots across its global network of 100 manufacturing plants by 2030, leveraging humanoid robots to boost operational efficiency. Agility Robotics CEO Peggy Johnson highlighted plans to deliver safe, human-cooperative robots outside traditional safety cages within the next 24 months, further advancing their Robots-as-a-Service (RaaS) model.
Read more via Agility Robotics.
Baidu says self-driving vehicle costs drop to US$34,525 as mass production ramps up (19/Nov/2024)
Baidu announced that the production cost of its Apollo RT6 self-driving vehicle has been reduced to US$34,525, making it the world’s only mass-produced Level 4 autonomous vehicle. CEO Robin Li highlighted this breakthrough as a competitive edge over rivals like Tesla. The reduction in costs is expected to accelerate the adoption of autonomous driving in China.
Read more via South China Morning Post.
BYD vs Tesla (20/Nov/2024)
This is a view of the BYD plant in China compared to the Tesla Gigafactory in the US. The scale of this one blew my mind…
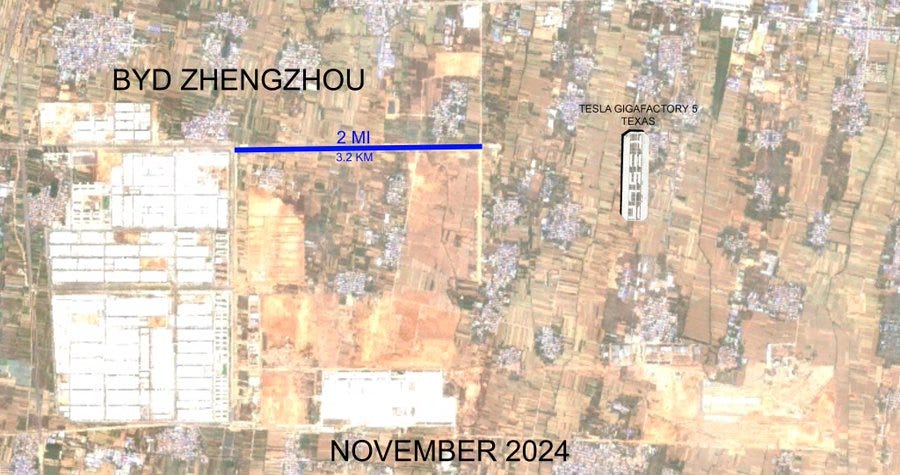
Source: https://x.com/taylorogan/status/1859146242519167249
O2 unveils Daisy, the AI granny wasting scammers’ time (14/Nov/2024)
O2 has introduced ‘Daisy’, an AI-powered ‘granny’ designed to waste scammers’ time with lifelike, autonomous conversations, keeping them occupied and away from real victims. Developed using cutting-edge AI and trained with scambaiter content, Daisy can engage fraudsters in lengthy calls, exposing their tactics while preventing them from targeting others.
Daisy isn’t available to the public, but it reminds me of some of the older versions:
2012: Lenny the telemarketer troll. I love this one so much, it’s not AI-based, but just waits for the telemarketer to pause and then plays a random clip of an old guy responding (like ELIZA) or even telling a long story. (Subreddit, listen to an 11min ‘bestof’ video with multiple calls, and a record 58min video with one telemarketer!)
2023: Jolly Roger via GPT-4
Read more via Virgin Media O2.
Zoom drops the ‘video’ from its company name (25/Nov/2024)
Zoom Video Communications Inc. has rebranded as Zoom Communications Inc., positioning itself as an “AI-first work platform for human connection.” The company is shifting focus from being synonymous with video conferencing to offering a full-suite solution, including productivity tools, business email, and AI automation through its Zoom Workplace platform. CEO Eric Yuan said the AI system:
…will translate into a fully customizable digital twin equipped with your institutional knowledge, freeing up a whole day’s worth of work and allowing you to work just four days per week.
Read more via The Verge.
Policy
Max Tegmark: If AGI arrives during Trump’s next term, ‘none of the other stuff matters’ (16/Nov/2024)
Max Tegmark, cofounder of the Future of Life Institute, reflects on the risks of AGI and the importance of proactive regulation. He views the 2023 open letter—signed by over 33,000 experts urging a pause in AI development—as a success in mainstreaming concerns about uncontrolled AI advancements. Tegmark warns that AGI’s emergence during a potential Trump presidency could overshadow all other priorities but suggests that figures like Elon Musk could influence the administration’s approach to managing AI responsibly.
Read more via Fast Company.
Related: Elon Musk's money is 'the reason we won,' Trump ally Steve Bannon says (27/Nov/2024). Read more via Quartz.
US Govt recommends a secret ‘Manhattan Project’ to reach AGI (27/Nov/2024)
The US-China Economic and Security Review Commission has proposed that Congress initiate a ‘Manhattan Project-like’ program to accelerate the development and acquisition of Artificial General Intelligence (AGI). The report suggests this effort is critical to maintaining national security and technological leadership, comparing the urgency to historical projects like the creation of atomic energy. This recommendation comes amidst global competition, particularly with advancements in AI by China.
Read the report (p10): https://www.uscc.gov/sites/default/files/2024-11/2024_Executive_Summary.pdf#page=10
I’ve added this as an INFO note to the AGI countdown: https://lifearchitect.ai/agi/
Anthropic, feds test whether AI will share sensitive nuke info (14/Nov/2024)
Anthropic is collaborating with the US Department of Energy’s National Nuclear Security Administration (NNSA) to test whether its Claude AI models, including Claude 3.5 Sonnet, could inadvertently share sensitive nuclear-related information. This pilot program, running since Apr/2024 and set to end in Feb/2025, marks the first known use of an advanced AI model in a top-secret environment. The goal is to identify and mitigate potential national security risks. The findings of this program remain undisclosed due to its sensitive nature.
Read more via Axios.
OpenAI to present plans for US AI strategy and an alliance to compete with China (13/Nov/2024)
OpenAI has unveiled its ‘blueprint for US AI infrastructure’, emphasizing AI economic zones, renewable energy projects, and leveraging the US Navy’s nuclear expertise for small modular reactors. The plan includes a North American AI alliance to counter China’s advancements and foresees significant investment, including billions in global funds, modernized energy grids, and new data centers in the Midwest and Southwest. OpenAI’s proposal also advocates for a ‘National Transmission Highway Act’ to meet AI-driven energy demands, projecting 50 gigawatts of energy needed by 2030.
Read more via CNBC.
OpenAI accidentally deleted potential evidence in NY Times copyright lawsuit (22/Nov/2024)
OpenAI engineers accidentally deleted search data during the NYT’s inspection for a copyright lawsuit, forcing plaintiffs to restart their analysis. While most data was recovered, missing folder structures made it unusable for verifying where copyrighted content was used in training. OpenAI denied wrongdoing, blaming a plaintiff-requested configuration change, while the NYT argued OpenAI should handle searches internally to prevent further issues.
Read more via TechCrunch and Ars Technica.
OpenAI countered by blaming the NYT for running flawed code and failing to back up data, while also offering to collaborate on targeted searches to avoid further issues.
Separately, the court rejected OpenAI’s attempt to include public benefits of AI tools in its fair use defense, narrowing its argument to whether copying NYT content specifically serves a public good. This ruling could weaken OpenAI’s position as the case moves toward a 2025 verdict.
Read more via Ars Technica.
Microsoft Copilot customers discover it can let them read HR documents, CEO emails (21/Nov/2024)
Microsoft’s Copilot AI tool has raised privacy concerns after users discovered it could provide access to sensitive internal documents, including CEO emails and HR files. The issue stems from lax permission settings in some companies, which Copilot exploits by indexing and surfacing all accessible information. Microsoft is addressing the problem with new tools and guidance to mitigate oversharing and improve governance.
Read more via Slashdot.
Google’s Anthropic deal at risk as DOJ seeks to resolve search antitrust case (21/Nov/2024)
The US Justice Department has proposed that Google must unwind its US$2B investment in AI startup Anthropic as part of resolving its landmark antitrust case over online search. The DOJ also recommended barring Google from acquiring or collaborating with companies controlling search-related technologies, including query-based AI products. This move highlights growing regulatory scrutiny over Google’s dominance in both search and AI markets.
Read more via Bloomberg.
Toys to Play With
Prompt injecting your way to shell: OpenAI's containerized ChatGPT environment (14/Nov/2024)
Explore how OpenAI’s containerized ChatGPT environment operates within a Debian-based sandbox, revealing its controlled file system and command execution capabilities. Through prompt injections, users can interact with internal directories, upload and execute Python scripts, and relocate files, showcasing the environment’s flexibility. OpenAI’s design intentionally allows these interactions in its sandbox; however, breaking out of this contained environment constitutes a genuine security vulnerability.
Read more via 0din.ai.
Scribe - Beautiful YouTube Transcripts with Gemini 1.5 Flash 8B LLM (2024)
Scribe uses the Gemini 1.5 Flash 8B LLM to enhance YouTube transcripts, transforming them into readable, well-structured formats. Users can compare the AI-corrected transcript with the original and search within transcripts for improved accessibility.
Read more via Readable Transcripts.
Skyvern - Automate browser-based workflows with AI (2024)
Skyvern streamlines repetitive, browser-based tasks using AI-powered automation. It adapts to any webpage, supports no-code and low-code workflows, and can handle complex operations like CAPTCHA solving, 2FA authentication, and data extraction. The platform is scalable, API-driven, and offers open-source access for developers, making it ideal for automating procurement, dynamic forms, and multilingual workflows.
Read more via Skyvern.
Runway: Introducing Frames (25/Nov/2024)
Runway’s Frames is a new image generation model that offers unmatched control over stylistic elements while maintaining high visual fidelity. Designed for creative projects, it excels in generating consistent variations tailored to specific aesthetics, allowing users to craft detailed worlds with precision. Frames is being integrated into Gen-3 Alpha and the Runway API, enabling seamless workflows for creators.
Read more via Runway.
Claude’s new 2,000-word system prompt (23/Nov/2024)
Claude follows this information in all languages, and always responds to the human in the language they use or request. The information above is provided to Claude by Anthropic. Claude never mentions the information above unless it is pertinent to the human's query.
See the new 23/Nov/2024 prompt.
It should be added to Anthropic’s official prompts repo soon: https://docs.anthropic.com/en/release-notes/system-prompts
PimEyes: Face recognition search engine and reverse image search (2017)
PimEyes uses advanced face recognition technology combined with reverse image search to locate photos containing a specific face across the open web.
I’ve been having a lot of fun with this, and it is extremely accurate. Try it yourself: submit a new photo of yourself and watch as AI ascertains who you are based on your face, and shows other images of you…
Try it: https://pimeyes.com/en
Wiki: https://en.wikipedia.org/wiki/PimEyes
Flashback
Hypothetical: What will GPT-2030 look like? (7/Jun/2023)
This was an interesting read more than a year ago, although it may already be out of date!
GPT-2030 is projected to be superhuman in specific tasks like coding, hacking, mathematics, and possibly protein design. It will process text up to 5x faster than humans (or 125x with higher compute investment) and perform 1.8M years of equivalent human work in just 2.4 months through parallelization. Additionally, GPT-2030 will likely integrate data from unconventional modalities like molecular structures and astronomical images, leading to capabilities far beyond human intuition in certain domains.
Read more via Bounded Regret.
Next
The next roundtable will be:
Life Architect - The Memo - Roundtable #21
Follows the Chatham House Rule (no recording, no outside discussion)
Saturday 7/Dec/2024 at 4PM Los Angeles (timezone change)
Saturday 7/Dec/2024 at 7PM New York (timezone change)
Sunday 8/Dec/2024 at 10AM Brisbane (primary/reference time zone)
or check your timezone via Google.
You don’t need to do anything for this; there’s no registration or forms to fill in, I don’t want your email, you don’t even need to turn on your camera or give your real name!
All my very best,
Alan
LifeArchitect.ai