


The Memo - 1/Apr/2024
DBRX 132B, companies spend $18M avg on LLMs, OpenAI Voice Engine, and much more!

To: US Govt, major govts, Microsoft, Apple, NVIDIA, Alphabet, Amazon, Meta, Tesla, Citi, Tencent, IBM, & 10,000+ more recipients…
From: Dr Alan D. Thompson <LifeArchitect.ai>
Sent: 1/Apr/2024 (31/Mar/2024 in US; all analysis as serious as ever)
Subject: The Memo - AI that matters, as it happens, in plain English
AGI: 72%I had a lot of fun at a datacenter next door to me (thanks to Stuart and Marie!) that features a world-leading patented innovation: tanks of non-conductive mineral oil with NVIDIA A100s (and other chips) completely submerged in the liquid for cooling purposes. This DC was designed and patented in Perth, Western Australia. It is really, really strange to see all electronics—including power connectors—completely submerged in liquid.
It was also just a little bit emotional to be in the same kind of ‘hospital’ as the one that gave birth to Leta AI and GPT-3 (V100s), ChatGPT, GPT-4, DALL-E, and much more. (Except this hospital specializes in water births!) You can read more about the patented design with specs here: https://dug.com/dug-cool/

The BIG Stuff
Andreessen Horowitz: 16 Changes to the Way Enterprises Are Building and Buying Generative AI (21/Mar/2024)
Andreessen Horowitz has interviewed many Fortune 500s in the ‘technology, telecom, CPG [Consumer Packaged Goods], banking, payments, healthcare, and energy’ fields about their use of large language models.
The findings are sensational. Here are my ‘top 3’ charts, beginning with the outrageous 2024 expected LLM spend of US$18,000,000 per company. It is interesting to see that 100% of these companies used OpenAI models (probably via Microsoft Azure OpenAI or Microsoft Copilot, rather than ChatGPT Enterprise).
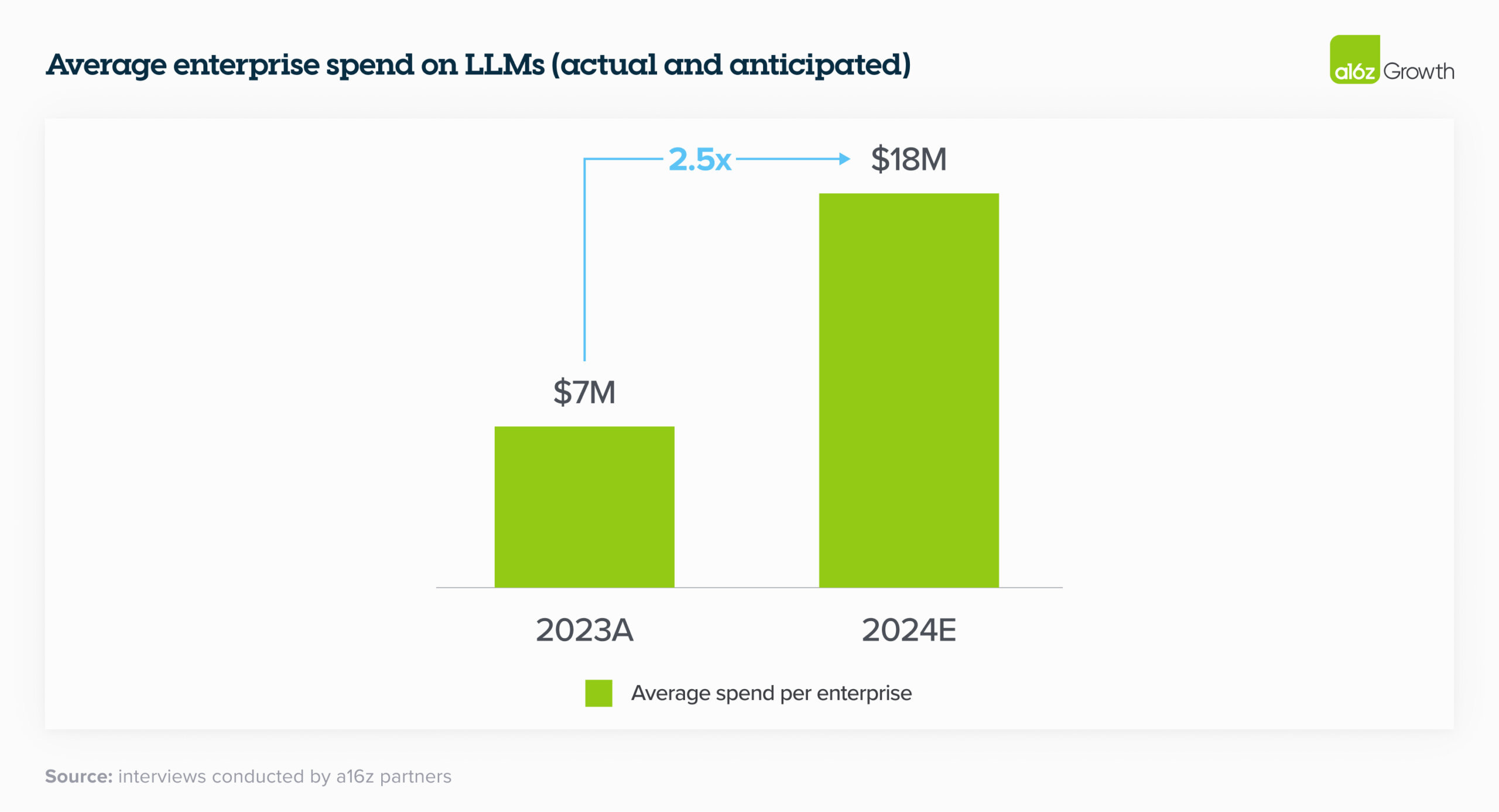
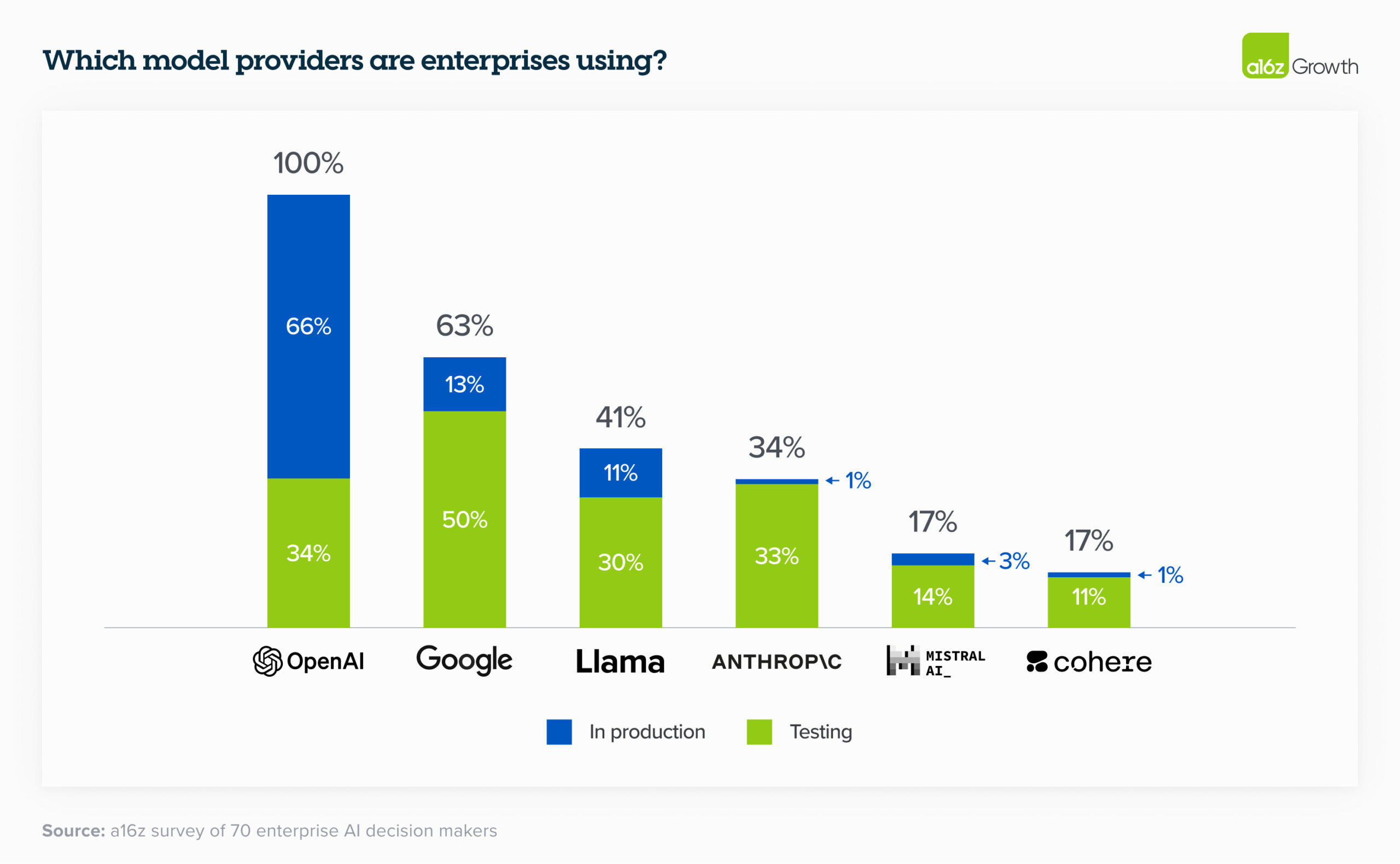
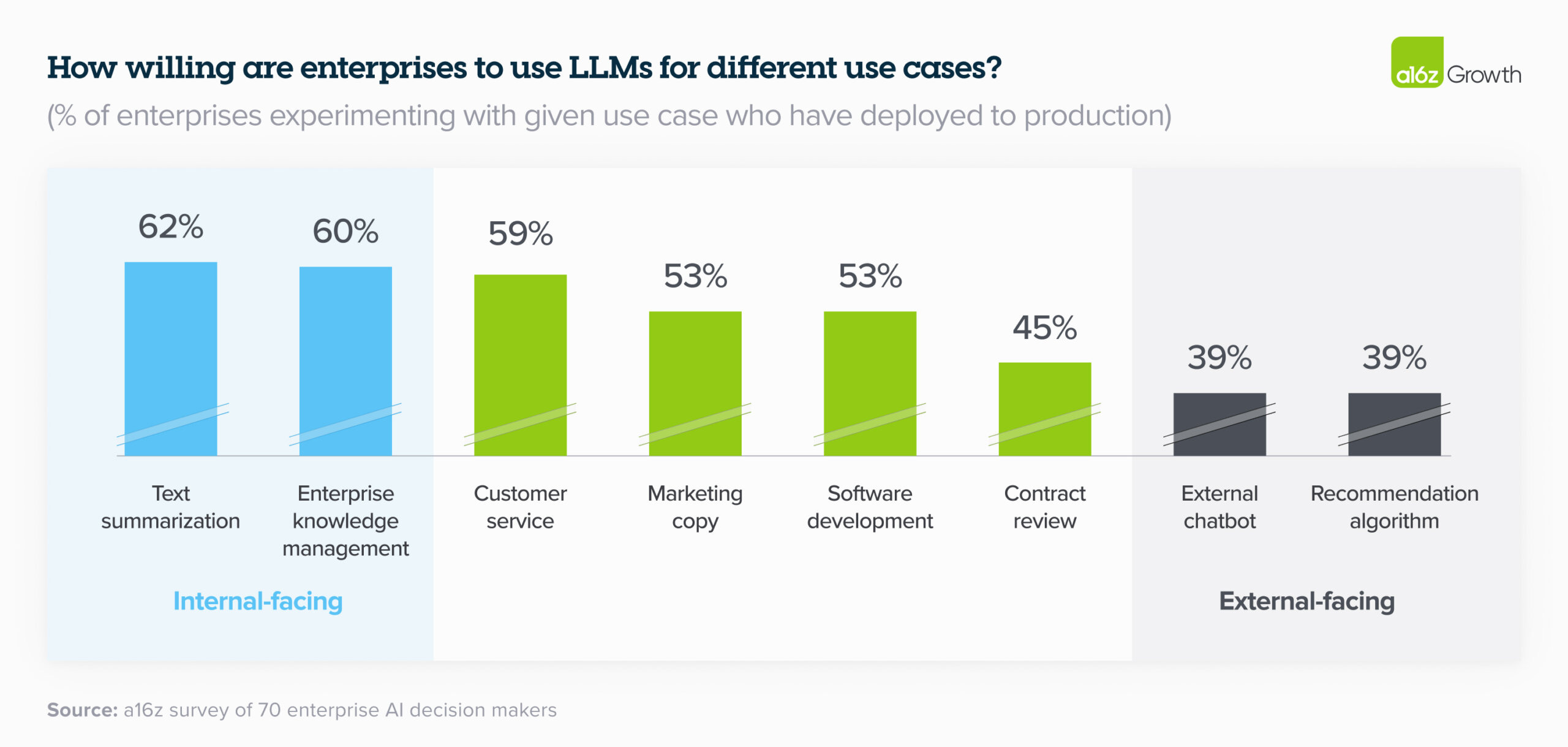
Later in this edition we look at 200 use cases for post-2020 AI.
Read more: https://a16z.com/generative-ai-enterprise-2024/
Sidenote: Here is one of my newest (and simplest!) slides, added this month for a 2-hour workshop on Microsoft Copilot for Microsoft 365, delivered to a major utility provider:

Full subscribers can watch some of my keynote rehearsals and recorded presentations here:

Red Lines (10/Mar/2024)
On 10 March 2024, leading global AI scientists met in Beijing, China in collaboration with the Beijing Academy of AI (BAAI). They signed a ‘Red Lines’ document.
This definitely fits under The BIG Stuff heading, but it’s unusually long so I provide full commentary in the Policy section of this edition.
56 new models announced in Q1 2024 (Apr/2024)
That was a massive first quarter. I can’t believe it’s over and we’re in April already. That means we’re half way to my next ‘The sky is…’ AI report.
Claude 3 Opus helped format this list of 56 LLM highlights announced this quarter, using data from my Models Table (you can see my prompt and conversation here 26/Mar/2024):
January 2024
JPMorgan DocLLM 7B, SUTD/Independent TinyLlama 1.1B, Tencent LLaMA Pro 8.3B, DeepSeek-AI DeepSeek 67B, DeepSeek-AI DeepSeekMoE 16B, Zhipu AI (Tsinghua) GLM-4 200B, Adept Fuyu-Heavy 120B, Tencent FuseLLM 7B, DeepSeek-AI DeepSeek-Coder 33B, Cornell MambaByte 972M, LMU MaLA-500 10B, RWKV RWKV-v5 Eagle 7B, Meta AI CodeLlama-70B, Apple MGIE 7B, iFlyTek Xinghuo 3.5 (Spark) 200B, iFlyTek iFlytekSpark-13B, Mistral AI miqu 70b, AIWaves.cn Weaver 34B.
February 2024
Cerebras FLOR-6.3B, Allen AI OLMo 7B, Google TimesFM 200M, AI Singapore Sea-Lion 7.5B, ChatDB Natural-SQL-7B, BRAIN GOODY-2, Alibaba Qwen-1.5 72B, Google DeepMind Gemini 1.5 Pro MoE, Google DeepMind Gemma 7B, Reka AI Reka Flash 21B, Reka AI Reka Edge 7B, Apple Ask 20B, Reliance Hanooman 40B, Mistral AI Mistral Large 540B, Mistral AI Mistral Small 7B, ByteDance 175B, ByteDance 530B, HF/ServiceNow StarCoder 2 15B, HF Cosmo-1B, SambaNova Samba-1 1.4T CoE.
March 2024
Anthropic Claude 3 Opus 2T, SRIBD/CUHK Apollo 7B, Inflection AI Inflection-2.5 1.2T, Stability AI Stable Beluga 2.5 70B, Fudan University AnyGPT 7B, DeepSeek-AI DeepSeek-VL 7B, Cohere Command-R 35B, Covariant RFM-1 8B, Apple MM1, RWKV RWKV-v5 EagleX 7.52B, Independent Parakeet 378M, Rakuten Group RakutenAI-7B, Sakana AI EvoLLM-JP 10B, Stability AI Stable Code Instruct 3B, MosaicML DBRX 132B MoE, AI21 Jamba 52B MoE, xAI Grok-1.5 314B, Alibaba Qwen1.5-MoE-A2.7B 14.3B MoE.
The final five bolded models were all announced in about a 24-hour period just before the Easter weekend.
See them on the Models Table: https://lifearchitect.ai/models-table/
The Interesting Stuff
Paper: GPT-4 can help fly a plane (25/Mar/2024)

I don’t list a ‘paper of the week’ in these editions, but if I did, this would be my favorite paper this week. Absolutely outrageous, and an incredible case study by the research team.
[GPT-4V and GPT-4 was used] to interpret and generate human-like text from cockpit images and pilot inputs, thereby offering real-time support during flight operations. To the best of our knowledge, this is the first work to study the virtual co-pilot with pretrained LLMs for aviation...
The case study revealed that GPT-4, when provided with instrument images and pilot instructions, can effectively retrieve quick-access references for flight operations. The findings affirmed that the V-CoP can harness the capabilities of LLM to comprehend dynamic aviation scenarios and pilot instructions.
Remember that GPT-4 is coming up to its 2nd birthday (it was ready in the OpenAI lab back in August 2022), and we’re still discovering its capabilities…
Read the paper: https://arxiv.org/abs/2403.16645v1
See my list of GPT achievements.
GPT-6 (Mar/2024)
I like to keep on the ‘bleeding edge’ of AI, but this one came quicker than even I was prepared for. GPT-5 isn’t even ready yet, and here are updates about GPT-6’s setup.
This is another advisory-grade edition. Let’s look at a lot more AI, including major new datasets, my Red Lines analysis, new Sora details, the AI platform replacing TIkTok, 200 use cases for post-2020 AI, two companies commit a quarter trillion dollars to datacenters, and much more…
Here’s the first rumor from former Google engineer Kyle Corbitt (Twitter, 26/Mar/2024):
Spoke to a Microsoft engineer on the GPT-6 training cluster project. He kvetched about the pain they’re having provisioning infiniband-class links between GPUs in different regions. Me: “why not just colocate the cluster in one region?” Him: “Oh yeah we tried that first. We can’t put more than 100K H100s in a single state without bringing down the power grid.” 🤯
NVIDIA H100 @ 700W x 100,000 = 70,000,000W = 70,000kW = 70MW. Claude 3 Opus told me:
70 megawatts (MW) is a significant amount of power. To put it in perspective, this is roughly the amount of electricity needed to power a small city or a large town.
For example, a city with around 70,000 households, assuming an average household consumes about 1 kW consistently, would require approximately 70 MW of power.
And, as detailed in The Memo edition 2/Dec/2023, Microsoft does indeed have an extra 150,000 H100s as of 2023:
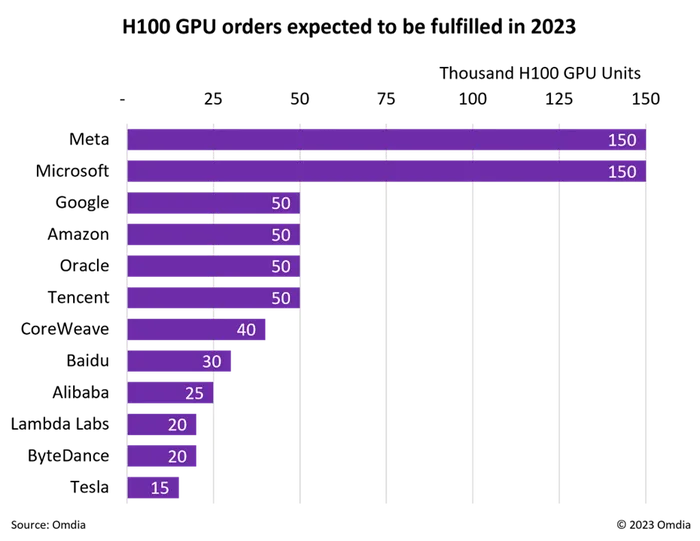
Read more: https://lifearchitect.ai/gpt-6/
Amazon Bets $150B on Data Centers Required for AI Boom (28/Mar/2024)
Amazon.com Inc. plans to spend almost US$150 billion in the coming 15 years on data centers, giving the cloud-computing giant the firepower to handle an expected explosion in demand for artificial intelligence applications and other digital services.
Read more via Bloomberg.
Microsoft and OpenAI planning $100B data center project - Information reports (29/Mar/2023)
Microsoft and OpenAI are planning to invest as much as US$100B over multiple years to build a series of data centers dedicated to AI, according to two people briefed on the plan.
Read more via Reuters.
OpenAI May Develop Own AI Chips with Samsung and SK Hynix (30/Jan/2024)
This rumor has been refreshed in March 2024, but here is the original source from two months ago.
Sam Altman, CEO of OpenAI, met with Samsung and SK Hynix executives in South Korea to discuss potential collaboration on developing AI chips, which could signal a new strategic direction for OpenAI.
Altman is currently engaged in discussions with potential major investors, including Abu Dhabi-based G42 and SoftBank Group Corp, to establish a multi-billion dollar global network of AI chip factories.
Taiwan Semiconductor Manufacturing Co (TSMC) is allegedly involved in these negotiations. The resulting chip entity could function as an independent company with OpenAI as its primary client or operate as a subsidiary of OpenAI.
Read more via KoreaTechToday.
MosaicML releases DBRX 132B (28/Mar/2024)
MosaicML and Data Bricks have released DBRX, a 132B-parameter MoE (mixture of experts) model. There is both a base model and a fine-tuned model release, with 16 experts.
This is the one of the largest open and publicly available model as of Mar/2024, still beaten by xAI’s Grok-1 314B MoE model (also from March 2024) and Falcon 180B. DBRX arguably outperforms even the larger Grok-1 on some benchmarks.
DBRX has 16 experts and chooses 4, while Mixtral and Grok-1 have 8 experts and choose 2. This provides 65x more possible combinations of experts and we found that this improves model quality.
Read the announce, download the weights, or try the demo (free, no login).
See it on the Models Table: https://lifearchitect.ai/models-table/
OpenAI Voice Engine (24/Mar/2024)
A 2016 Stanford study (25/Aug/2016) found that speaking is 3× faster than typing on a keyboard.
I am certain that over the next few months—before we get to full thought transfer—voice interaction will become the standard. It wasn’t very nice in the 1990s with products like Dragon Naturally Speaking (I remember manually ‘training’ that thing for hours on my Windows 95 machine), but we’ve improved with post-2020 AI models like OpenAI’s Whisper.
Now, OpenAI has applied for ‘VOICE ENGINE™’ as a trademark registration. As usual, this trademark has a long list of classes, uses, and descriptions including:
voice and speech recognition, processing voice commands, and converting between text and speech;
We’ve covered several of OpenAI’s trademark applications in The Memo, and I expect to see this in a new product shortly…
Read the application: https://uspto.report/TM/98456635
OpenAI released a ‘say nothing’ post about this technology (29/Mar/2024).
Amazon spends US$4B total on Anthropic in largest venture investment yet (27/Mar/2024)
Amazon has committed an additional US$2.75 billion [adding to its initial US$1.25B investment for a total of US$4B!] to AI startup Anthropic, marking its largest external investment to date, as part of a strategic collaboration to advance generative AI technology.
Remember, it seemed like a big leap when Microsoft first invested $1B in OpenAI in 2019.
$4B seems to be a big number now, but will only get bigger. Wait for the trillions spent on AI training (besides Altman seeking $7T for hardware).
Read the official announce via Amazon.
Read more via CNBC.
New Sora details (26/Mar/2024)
Factorial Funds has analyzed costing for a Sora-like model.
Sora requires a huge amount of compute power to train, estimated at 4,200-10,500 Nvidia H100 GPUs for 1 month.
For inference, we estimate that Sora can at most generate about 5 minutes of video per hour per Nvidia H100 GPU [or 12 minutes of processing to generate 1 minute of video]. Compared to LLMs, inference for diffusion-based models like Sora is multiple orders of magntitude more expensive.
Assuming significant AI adoption for video generation on popular platforms like TikTok (50% of all video minutes) and YouTube (15% of all video minutes) and taking hardware utilization and usage patterns into account, we estimate a peak demand of ~720,000 Nvidia H100 GPUs for inference.
Read more: https://factorialfunds.com/blog/under-the-hood-how-openai-s-sora-model-works
Here’s a great example of Sora being prompted by a film director (link):
Watch more via OpenAI: https://openai.com/blog/sora-first-impressions
Dataset: Cosmopedia: how to create large-scale synthetic data for pre-training Large Language Models (20/Mar/2024)
Cosmopedia is the largest open synthetic dataset to date, containing over 30 million files and 25 billion tokens generated by Mixtral-8x7B-Instruct-v0.1. It aims to reproduce the training data used for Microsoft's Phi-1.5 model to enable the community to build upon the approach of pre-training models on high-quality synthetic data.
…in reality most of the time for Cosmopedia was spent on meticulous prompt engineering…
Generating synthetic data might seem straightforward, but maintaining diversity, which is crucial for optimal performance, becomes significantly challenging when scaling up. Therefore, it's essential to curate diverse prompts that cover a wide range of topics and minimize duplicate outputs, as we don’t want to spend compute on generating billions of textbooks only to discard most because they resemble each other closely. Before we launched the generation on hundreds of GPUs, we spent a lot of time iterating on the prompts with tools…
Considering our goal of generating 20 billion tokens, we need at least 20 million prompts!
By targeting four different audiences (young children, high school students, college students, researchers) and leveraging three generation styles (textbooks, blog posts, wikiHow articles), we can get up to 12 times the number of prompts.
If you’d like to learn more about how synthetic datasets are generated, this is a really well-written piece, and an excellent read (in plain English!).
Sidenote: This is my personal highlight of this edition. Fascinating stuff.
Read more via Hugging Face blog.
Dataset: Pleias Common Corpus (Mar/2024)
French AI lab Pleias has announced a new dataset called ‘Common Corpus’ (not to be confused with related datasets ‘Common Crawl’ or Google’s ‘Colossal Clean Crawled Corpus‘). This one is only 500B tokens or 650B words; maybe around 2TB of text data:
Common Corpus is the largest public domain dataset released for training LLMs.
Common Corpus includes 500 billion words from a wide diversity of cultural heritage initiatives.
Common Corpus is multilingual and the largest corpus to date in English, French, Dutch, Spanish, German and Italian.
Common Corpus shows it is possible to train fully open LLMs on sources without copyright concerns.
Read more: https://huggingface.co/blog/Pclanglais/common-corpus
Download the dataset via HF.
See it (with the BigScience ROOTS dataset released this month) on my Datasets Table.
Microsoft Copilot AI will soon run locally on PCs (28/Mar/2024)
According to Intel, next-gen AI PCs running 'more elements of Copilot' locally would require built-in neural processing units (NPUs) with over 40 TOPS of power — beyond the capabilities of any current consumer processor.
TOPS stands for 'trillion operations per second' and is a measure of the AI processing speed of a chip's neural processing unit (NPU).
Read more via Engadget.
Profluent, spurred by Salesforce research and backed by Jeff Dean, uses AI to discover medicines (25/Mar/2024)
Profluent, a company emerging from Salesforce research, is leveraging artificial intelligence to design proteins and accelerate drug discovery, potentially revolutionizing the development of custom-fit treatments.
While at Salesforce’s research division, Madani found himself drawn to the parallels between natural language (e.g. English) and the “language” of proteins. Proteins — chains of bonded-together amino acids that the body uses for various purposes, from making hormones to repairing bone and muscle tissue — can be treated like words in a paragraph, Madani discovered. Fed into a generative AI model, data about proteins can be used to predict entirely new proteins with novel functions.
Read more via TechCrunch.
DIAMBRA Arena Environments (30/Mar/2024)

Evaluate Large Language Models (LLM) quality by having them fight in realtime in Street Fighter III. Who is the best? OpenAI or MistralAI? Let them fight! Open source code and ranking.
Making LLMs fight in realtime assess their speed and their reasoning abilities. LLMs have to quickly assess their environment and take actions based on it.
Official project page: https://docs.diambra.ai/projects/llmcolosseum/
Competition platform: https://diambra.ai/
Browse the DIAMBRA Github repo: https://github.com/diambra
Mamma Mia star Sara Poyzer is replaced by AI for BBC production (27/Mar/2024)
Sara Poyzer, known for her role in "Mamma Mia," was replaced by AI for a BBC production, an event she described as 'sobering' and indicative of 'grim times' for the acting industry.
the email was a response from a production company that was working with the BBC on a project hoping to hire Ms Poyzer.
Ms Poyzer was waiting to hear back on whether it had been confirmed but was told they would be using AI instead.
Read more via Daily Mail.
Filtered: How People Are Really Using GenAI (19/Mar/2024)
Real people are really getting plenty from generative AI… it’s actually creating value in people’s personal and professional lives. With any popular new technology, there are many fans and many detractors, like the two skeptics at the beginning of this piece. Who will have the last laugh though? The gleeful celebration of AI tripping up is irresistible and will do the social media rounds, for now. But whereas the appeal of this schadenfreude will fade, the real stories of AI helping human lives will stay and spread. As one enthusiast said “People that don’t find it useful, simply haven’t really understood how to use it.” Another put it more sharply: “The 5% or whatever who use it effectively are going to smoke the others.”

Read more via HBR or the original source. Or download the full report (101 pages, 5MB):
Compare this with the UAE Govt’s similarly titled ‘100 Practical Applications and Use Cases of Generative AI‘ from a year ago (Apr/2023, 119 pages, 7MB):
Policy
Red Lines (10/Mar/2024)
On 10 March 2024, leading global AI scientists met at the Aman Summer Palace in Beijing, China in collaboration with the Beijing Academy of AI (BAAI).
Of all the hundreds of AI acts and guidelines that have been processed in the last 36 months, this may be the most significant. Several pioneering AI researchers—including Prof Yoshua Bengio (wiki) and Prof Geoffrey Hinton (link)—are leading signatories.
There are some thoughtful parts do the document. And while I do applaud cooperation between leaders in the US and China (and each of the 24 signatories, including representatives from GovAI) for their focus on safety, I was disquieted by the first two key points:
Autonomous Replication or Improvement
No AI system should be able to copy or improve itself without explicit human approval and assistance. This includes both exact copies of itself as well as creating new AI systems of similar or greater abilities.
Power Seeking
No AI system should take actions to unduly increase its power and influence.
These are concerning, as they preclude continuing evolution of AI to AGI to ASI (superintelligence). If humanity had gone down this road at the birth of fire or electricity or the internet, I wouldn’t be here writing this, and you wouldn’t be here reading it. The entire ‘Red Lines’ document reads as an exercise in alarmist and negligent rhetoric. Even one of the opening sentences has the whole concept of post-2020 AI backwards:
‘In the depths of the Cold War, international scientific and governmental coordination helped avert thermonuclear catastrophe.’
Comparing humanity’s evolution through increased intelligence to US-Soviet power politics is… well, I’ll leave it up to you to come up with your own describing word.
Notably, Yoshua was born in 1964, Hinton in 1947, so I do wonder if their fearful views may be directly colored by their experiences of the irrational paranoia at that time (remember ‘reds under the bed’? - wiki). The way I see it, these guys and this document are on the wrong side of history. This lazy and default ‘resistance to change’ is not helpful. At least in this case, the Western media ignoring China (as usual) may be a good thing.
Sidenote: If you need some mind bleach, let me take you back a few weeks to January 2024, when DeepMind used a large language model to solve new problems: ‘this is the first time that a genuine, new scientific discovery has been made by a large language model… It’s not in the training data—it wasn’t even known.‘ (DeepMind and more sources via my AGI countdown)
The reason we are here right now—our inventions, evolution, technology—is the result of many of the smartest people in the world bringing us to this point. That time is now over, and AI is primed to take on the role of inventor and more. Watching smart people rail against increased smarts is infuriating. I am counting down the days until superintelligence begins creating new ways of doing things—and yes, creating new AI systems—using a ‘mind’ that is 1,000,000× smarter than any professor.
Read the Red Lines document: https://idais-beijing.baai.ac.cn/?lang=en
Read a short analysis (with photo) by FT and another (with photo) by FAR AI.
Biden orders every US agency to appoint a chief AI officer (28/Mar/2024)
The White House has announced a government-wide policy to mitigate AI risks and harness its benefits, requiring every federal agency to appoint a chief AI officer with 'significant expertise in AI' within the next 60 days.
To ensure accountability, leadership, and oversight for the use of AI in the Federal Government, the OMB policy requires federal agencies to:
Designate Chief AI Officers, who will coordinate the use of AI across their agencies. Since December, OMB and the Office of Science and Technology Policy have regularly convened these officials in a new Chief AI Officer Council to coordinate their efforts across the Federal Government and to prepare for implementation of OMB’s guidance.
Establish AI Governance Boards, chaired by the Deputy Secretary or equivalent, to coordinate and govern the use of AI across the agency. As of today, the Departments of Defense, Veterans Affairs, Housing and Urban Development, and State have established these governance bodies, and every CFO Act agency is required to do so by May 27, 2024.
Sidenote: The Federal Register show a list of all 438 agencies and sub-agencies: https://www.federalregister.gov/agencies
Read more via Ars Technica.
Read the White House announce.
Dr Demis Hassabis knighted (28/Mar/2024)
I wonder if this really belongs under ‘policy’… As the first AI expert given this honor (apparently Turing was not considered suitable for a knighthood due to views on sexuality at the time), I certainly thought it was interesting, and has a big impact on government recognition of AI.
Read more via the Independent.
Toys to Play With
TheMemoLinkThinkBot (28/Mar/2024)
I first released this bot back in The Memo edition 10/Oct/2023. I’ve now updated it with more complex logic, and replaced the old GPT-4 model with the current SOTA model, Claude 3 Opus. You should be able to see the full prompt as it is public, or you can reply to this email and we’ll get you a copy. The bot now seems to work nearly every time! I use this bot for grabbing and formatting titles and dates from releases, as well as some link summaries for these editions.
Try it (paid, login): https://poe.com/TheMemoLinkThinkBot
Arcads (Mar/2024)
I’m definitely not promoting this (I don’t do promotions), and the AI being applied is very basic—just video input + AI voice + AI lipsync—but the outputs are interesting. This may begin replacing TikTok and ‘vlogging’. Here’s how Arcads articulates its offering in the Terms & Conditions:
a catalogue of [real, filmed] videos made by different creators (the “Creators”) in different environments, each with its own particularities (the "Video Models")… the option of uploading a script (the "Script") to the Platform in order to create a final video (the "Video") which, on the basis of the Video Model chosen, integrates the script, in particular by making the lip-sync and cloning the voice with that of the Video Model Creator or another Creator. (Arcads’ Terms)
Take a look at a real example on Twitter (warning: it is an ad): https://twitter.com/beckylitv/status/1772407948481892396
Official site: https://www.arcads.ai/
A look behind the scenes: https://youtu.be/gWNtOqesF4Q
PowerShell Module: PSPoe (30/Mar/2024)
PSPoe is a PowerShell module designed to streamline interaction with the Poe.com LLM API.
Check it out: https://github.com/jmangold23/pspoe
Books (Mar/2024)
Last edition I mentioned that I had pre-ordered a book called Deep Utopia. The style was not for me, and I have returned it for a refund. With the pace of change—and the creative/intellectual power of LLMs—books are over. Books written by verbose and meandering professors are definitely over…
Rabbit partners with ElevenLabs to power voice commands on its device (27/Mar/2024)

Rabbit has announced a partnership with ElevenLabs to integrate voice command technology into its upcoming r1 devices, enhancing the user experience with more human-like interactions.
Read more via TC.
Pre-order for US$199: https://www.rabbit.tech/
Hume AI: Empathic AI voice (27/Mar/2024)
This one is a lot of fun. I could only get it working on my mobile device (not on my laptop browser). It is able to ‘hear’ tone in your voice, and respond accordingly.
EVI has a number of unique empathic capabilities
1. Responds with human-like tones of voice based on your expressions
2. Reacts to your expressions with language that addresses your needs and maximizes satisfaction
3. EVI knows when to speak, because it uses your tone of voice for state of the art end-of-turn detection
4. Stops when interrupted, but can always pick up where it left off
5. Learns to make you happy by applying your reactions to self-improve over time Of course, it includes fast, reliable transcription and text-to-speech and can hook into any LLM.
Read the announce: https://twitter.com/hume_ai/status/1773017055974789176
Try it (free, no login): https://demo.hume.ai/
Flashback
I feel like I’ve lived 30 years in the last three years. Leta AI’s first episode was 9/Apr/2021. I remastered the audio using AI more recently (in 2023).
Leta, GPT-3 AI - Episode 1 (Five things, Art, Seeing, Round) - Chat with GPT3 [Remaster]
Watch my video (link):
Next
The next roundtable will be:
Life Architect - The Memo - Roundtable #9
Follows the Chatham House Rule (no recording, no outside discussion)
Saturday 6/Apr/2024 at 5PM Los Angeles
Saturday 6/Apr/2024 at 8PM New York
Sunday 7/Apr/2024 at 8AM Perth (primary/reference time zone)
or check your timezone via Google.
You don’t need to do anything for this; there’s no registration or forms to fill in, I don’t want your email, you don’t even need to turn on your camera or give your real name!
All my very best,
Alan
LifeArchitect.ai
Best takeaway Allan is your skepticism about how the scientific community got us through the cold war without annihilation. Weren't they the ones working so hard on the Manhattan project to give us all the means of annihilation? AI may be able to tell us how we survived it all.
I actually have to disagree with you, Alan, and agree with those first two Red Lines!
I don't think they preclude us from using AI to improve AI, as you intimated, they just make sure that humans are kept in the loop. That makes good sense to me, as obviously there is unknown danger in a runaway and possibly exponential process that gets beyond our control.