
The Memo - 17/Aug/2023
Stability AI's new LLMs, chips and politics, Unitree H1 robot, and much more!

FOR IMMEDIATE RELEASE: 17/Aug/2023
Bill Gates on GPT-4 passing the AP Biology exam (11/Aug/2023 or
watch my video about this quote):
It's the most stunning demo I've ever seen in my life, right up there with seeing the Xerox PARC graphics user interface that set the agenda for Microsoft... this demo was so surprising to me, the emergent depth that as they scaled up the training set, its fluency and you have to say understanding…
I'm still, personally, in a state of shock at ‘Wow, it is so good’.
Welcome back to The Memo.
You’re joining full subscribers from BlackRock, Boeing, BAAI, Brainware.io, BAE Systems, BSH Hausgeräte, Berkeley, Boston Consulting Group, and more…
The chip edition! In this edition, we spend time putting the recent GPU chip distribution into plain English, looking at a new chip company to compete with NVIDIA, and hearing from the man who made GPT-3 and Claude. In the Toys to play with section, we look at new on-device Llama 2 models, slide decks designed by AI, a global map of robotaxis, and the coolest new audio AI model.
The next roundtable for full subscribers will be very soon:
Life Architect - The Memo - Roundtable #2 with Harvey Castro
Saturday 26/Aug/2023 at 5PM Los Angeles
Saturday 26/Aug/2023 at 8PM New York
Sunday 27/Aug/2023 at 8AM Perth (primary/reference time zone)
or check your timezone.
Details at the end of this edition.
The BIG Stuff
Where will AGI begin? (Aug/2023)
OpenAI defines artificial general intelligence (AGI) as ‘highly autonomous systems that outperform humans at most economically valuable work.’
We can now estimate with a little more certainty when AGI will be here (hint: in around 23 months from now; mid-2025). But what about where? I was discussing this recently with a colleague, and posing China as a potential leader in delivering AGI first. Here’s a new viz showing my top three picks for the exact location of the first AGI system.

If you live in one of these cities (perhaps with the exception of sunny London!), you’re already exposed to bleeding-edge technology like 24x7 driverless robotaxis, very high-speed Internet, streamlined access to society via mobile apps, automated deliveries—sometimes within minutes of purchase, and much more. It’s not such a stretch to imagine a human-level machine being produced in an AI lab in one of these cities very soon.
Bonus: Back in Jul/2016, OpenAI admitted that one of their special projects is to monitor for stealth AGI release by another lab: ‘Detect if someone is using a covert breakthrough AI system in the world… the probability increases that an organization will make an undisclosed AI breakthrough… It seems important to detect this. We can imagine a lot of ways to do this—looking at the news, financial markets, online games, etc.’
Read more: https://lifearchitect.ai/agi/
Stability AI unleashes many open-source models (Aug/2023)

Stability AI were on fire in the last few weeks. Their major language model announcements include:
Released a Japanese model, Japanese StableLM Alpha 7B, the best-performing openly available language model for Japanese speakers (link).
Released a code model, StableCode 3B trained on The Stack dataset, and with a context window of 16,384 tokens (link).
Released their ChatGPT competitor Stable Chat: research.stability.ai/chat.
Renamed their fine-tuned FreeWilly models to Stable Beluga 1 65B and Stable Beluga 2 70B (based on Llama 1 and Llama 2) (link).
Stability AI’s instruction tuned version of Llama 2 Stable Beluga 2 70B does very well in English assessments like the SAT, even outperforming OpenAI’s ChatGPT:

Make sure you try Stable Chat (free, login): research.stability.ai/chat
Advanced use cases for LLMS: Agriculture (15/Aug/2023)
I’m considering running a series about advanced use cases of LLMs around the world, on the way to having these models actually invent new things, present new theorems and proofs, discover new materials, and more broadly augment our human capacity.
The following article is about ‘genAI’ [what a lame buzzword; it just means AI based on large language models or other models that can generate completions] being applied to agriculture in India:
According to a recent report [ARK 2/Aug/2023], AI and precision agriculture have the potential to bring down annual agricultural operating costs by over 22% globally.
Plantix, a Germany-based agritech firm focused on India, is testing genAI on its plant disease diagnosis platform. Users can get a diagnosis as well as suggestions for remedies and preventive measures by capturing and uploading a plant image on the app.
Meanwhile, Cropin, a precision-farming firm established in 2010, is using genAI to rebuild satellite data obstructed by clouds.
On the other hand, products like Kissan AI, FarmerChat, and Jugalbandi are introducing ChatGPT-like conversational AI products for farming…
Some companies like Sagri, Cropin, and Satyukt are taking a different approach when it comes to integrating genAI into agriculture. Instead of focusing on chatbots, they use AI, machine learning, and remote sensing to create an intelligent, interconnected data platform…
Read more via TechInAsia: https://archive.md/fUdvA
Some of these advanced LLM use cases for agri seem similar to several earlier reports in The Memo of LLM use in defense: notably Palantir AIP (video) and Scale AI Donovan (video).
I’ve said it many times: human imagination is the main limitation of post-2020 AI. We still don’t know how these superhuman models work (and we don’t really need to), and we are still finding ways to apply this superhuman intelligence to our human challenges.
Unitree H1 humanoid robot (15/Aug/2023)

Here it is, China’s latest copy of a humanoid robot. H1 is 47kg, about 180cm, and available for under US$90,000.
This thing is FAST, the fastest robot I’ve seen, running at more than 18km/h (for humans, men run at 13km/h and women at 10km/h on average).
Read more: https://www.unitree.com/en/h1/
Watch the video (link):
The Interesting Stuff
China + GPUs (10/Aug/2023)
A graphics processing unit (GPU) is a computer chip that renders images by performing rapid mathematical calculations. Over the last few years, researchers have been using clusters of thousands of GPUs to accelerate AI and large language model workloads.
This stuff might seem nerdy, but consider that with the advent of AGI, GPUs will increasingly run our entire lives, becoming more important than the electrical transformer, internal combustion engine, or even the Internet (NVIDIA calls it ‘the Most Important Work of Our Time’).
Alibaba Group Holding Ltd. hasn’t been able to completely fulfill demand for AI training from clients because of global supply constraints, its top executive said, suggesting a shortage of critical components such as artificial intelligence chips is weighing on Chinese efforts to ramp up in the cutting-edge technology…
A shortage of high-powered semiconductors is undermining Chinese efforts to keep pace with the US in AI. Washington has banned Chinese firms from buying the most advanced chips made by Nvidia Corp., impeding attempts to build rivals to OpenAI’s ChatGPT. Nvidia has since created an inferior version of its most potent A100 chips for the country, and major Chinese tech firms including Alibaba have reportedly placed billions of dollars’ worth of orders.
Alibaba, Baidu, ByteDance, and Tencent have placed orders worth $1 billion to buy about 100,000 of Nvidia’s A800 processors, which will be delivered this year. The four Chinese tech giants also bought $4 billion worth of NVDA’s graphics processing units (GPUs) to be delivered in 2024.
Nvidia offers its A800 processor in China to abide by the U.S. export control rules, which banned the sale of two advanced chips – the A100 and H100. These two advanced chips are used for high-performance computing and for training AI models. The A800 GPUs have slower data transfer rates than the A100s… [Alan: see details below.]
ByteDance, which owns the video-sharing social media app TikTok, has reportedly stockpiled at least 10,000 Nvidia chips to support its AI projects. Additionally, it has placed orders for about 70,000 A800 chips for nearly $700 million, to be delivered in 2024.

The only real difference between the A100 and the ‘made for China’ A800 is the chip-to-chip data transfer rate, also known as the interconnect, or what NVIDIA marks as the NVLink. The interconnect on the A100 for US operates at 600GB/sec, where the interconnect on the A800 for China operates at 400GB/sec; the US model runs at 150% the speed of the Chinese model.
Generalising this interconnect speed to model training time (although this is not really a great assumption), and in plain English, this would translate to training a large language model the size of GPT-3 in 51 days instead of 34 days. A huge difference if you’re in a rush to compete with other nations during humanity’s biggest evolutionary process…
Here’s an exclusive comparison of the two major cards side-by-side using NVIDIA’s spec sheets:

Notably, NVIDIA’s most sought-after GPU for LLM training right now is the larger NVIDIA H100, with up to 900GB/sec interconnect [225% the speed of the A800] and up to 188GB GPU memory (link). This hardware will no longer be available to China.
Read the gold-standard summary of NVIDIA H100 supply by GPU Utils (Aug/2023).
Despite Thomas L. Friedman’s assertion that The World Is Flat (wiki), this is a massive geo-political-socio-cultural-economic footnote in history:
NVIDIA was founded by both Chinese (the Republic of China, ROC) and American members, with a Taiwan-born CEO.
NVIDIA is headquartered in the US (incorporated in Delaware and based in Santa Clara, California).
NVIDIA is ‘fabless,’ meaning they don’t have their own fabrication facilities (also called foundries) or factories, instead relying on partners to make the chips.
NVIDIA’s H100 chips are actually made in Anding District, Tainan, Taiwan (ROC) by the Taiwan Semiconductor Manufacturing Co Ltd (TSMC) in a $20B facility called Fab 18 (source, wiki).
Just a 2-hour flight across the pond is mainland China (the People’s Republic of China, PRC). Parts of the NVIDIA fab process are also undertaken at TSMC’s Fab 10 in Songjiang, China (PRC), or Fab 16 in Nanjiing, China (PRC).
The US has now said that China (PRC) is not allowed to buy the most powerful NVIDIA chips, despite the fact that China actually makes those chips (manufactured in ROC, with some fab in PRC). Read The White House Executive Order (9/Aug/2023).
I wonder how we’ll view this decision to slow down competitors in a year or two…
Having been a permanent resident in PRC, and spent even longer in ROC, I look forward to AI helping out with stabilising these very strange geo-political tensions, and bringing much-needed diplomacy to the world.
Bonus: OpenAI’s big models were designed by Russian-born and Israel-raised Canadian Dr Ilya Sutskever, with a multinational team of mostly American, Indian, and Chinese developers, programmed in the Python language invented by a Dutchman, trained on global data in 90+ languages using Taiwanese hardware… and I suppose the kicker is that you’re getting this analysis from an Australian with a bit of Italian heritage!
Saudi Arabia + UAE + GPUs (14/Aug/2023)
Saudi Arabia has bought at least 3,000 of Nvidia’s H100 chips — a $40,000 processor…
“The UAE has made a decision that it wants to… own and control its own computational power and talent, have their own platforms and not be dependent on the Chinese or the Americans,” said a person familiar with Abu Dhabi’s thinking.
“Importantly, they have the capital to do it, and they have the energy resources to do that and are attracting the best global talent as well,” the person added…
According to multiple sources close to Nvidia and its manufacturer, Taiwan Semiconductor Manufacturing Company, the chipmaker will ship about 550,000 of its latest H100 chips globally in 2023, primarily to US tech companies…
In Saudi Arabia, Kaust will receive 3,000 of these specialist chips, worth about $120mn in total, by the end of 2023, according to two people close to the university’s AI labs.
The Saudi university, which, according to people close to Kaust, also owns at least 200 A100s, is building a supercomputer, Shaheen III, that will become operational this year. The machine will run 700 Grace Hoppers, Nvidia’s so-called superchips, designed for cutting-edge artificial intelligence applications…
Meanwhile, the UAE, which in 2017 was the first nation to establish an AI ministry, has launched a “Generative AI Guide” [PDF, Apr/2023] as part of the government’s “commitment to reinforcing its global position as a pioneer in technology and artificial intelligence sectors” as well as “regulatory frameworks to limit the negative use of technology”.
MatX: A new chip company for large language models (Aug/2023)
Mission:
Be the compute platform for AGI.
Make AI better, faster, and cheaper by building more powerful hardware.
Approach:
We target just LLMs, whereas GPUs target all ML models.
LLMs are different. Our hardware and software can be much simpler.
We combine deep domain experience, a few key ideas, and a lot of careful engineering.
Team:
Reiner Pope, CEO: helped build Google PaLM. Wrote Google's fastest inference software.
Mike Gunter, CTO: helped build Google TPUs. Designed or architected 11 chips across six industries.
Our team has deep experience in ASIC design, compilers, and high-performance software.
Read (not very much) more: https://matx.com/
NVIDIA unveils the GH200 (8/Aug/2023)

Up to 3.5x more memory capacity and 3x more bandwidth than the current generation offering — comprises a single server with 144 Arm Neoverse cores, eight petaflops of AI performance and 282GB of the latest HBM3e memory technology.
Read more: https://nvidianews.nvidia.com/news/gh200-grace-hopper-superchip-with-hbm3e-memory
Read analysis by Anandtech (29/May/2023).
Beginner’s guide to Llama models (12/Aug/2023)
Llama is the first major open-source large language model [Alan: No way. There were many popular models that came before it, this one is just seeing more publicity]… In addition to being free and open-source, it is pretty small and can be run on a personal computer. The 7-billion and 13-billion parameter models are very usable on a good consumer-grade PC.

Today’s most popular consumer grade GPU is the NVIDIA GeForce RTX 4090, with 24GB GPU memory (link), and priced around US$1,900. This is enough to run the 30B parameter Llama 2 model.
Sometimes people do my job for me and put today’s AI in plain English. This is one of those times. I’m not saying it’s perfect English, but it’s a great primer.
Read it: https://agi-sphere.com/llama-guide/
Microsoft Azure ChatGPT: Private & secure ChatGPT for internal enterprise use (Aug/2023)
One of the major concerns I hear in consulting to enterprise and government alike is that allowing staff to interact with LLMs is a safety issue. The feeling is that a user might talk with a model like ChatGPT about proprietary information, and then that information becomes part of ChatGPT, or may be used in the future for training.
While this is not likely to be true, it is not provably false. So the next best thing is hosting your own LLM (which has been possible for more than three years since GPT-3-like models), or to use an enterprise service like Microsoft Azure, which has also been available for quite a while now.
Bonus: Back in The Memo edition 27/Jan/2023, we reported that Wharton (UPenn) enforces the use of ChatGPT and text-to-image models. It is mandatory for students to use at university. If you’re not using this stuff in business, you’re already way behind. And given that AI-time might move at 10x the pace of regular time, you’d be more than six years behind.
Browse the repo (UI code only): https://github.com/microsoft/azurechatgpt
Microsoft walkthrough and video from Apr/2023.
Hugging Face Candle (Aug/2023)
Candle's core goal is to make serverless inference possible. Full machine learning frameworks like PyTorch are very large, which makes creating instances on a cluster slow. Candle allows deployment of lightweight binaries.
Browse the repo: https://github.com/huggingface/candle
Try Llama 2 using Candle in the browser (slow and heavy): https://huggingface.co/spaces/lmz/candle-llama2
Agents: MetaGPT: Meta Programming for Multi-Agent Collaborative Framework (1/Aug/2023)
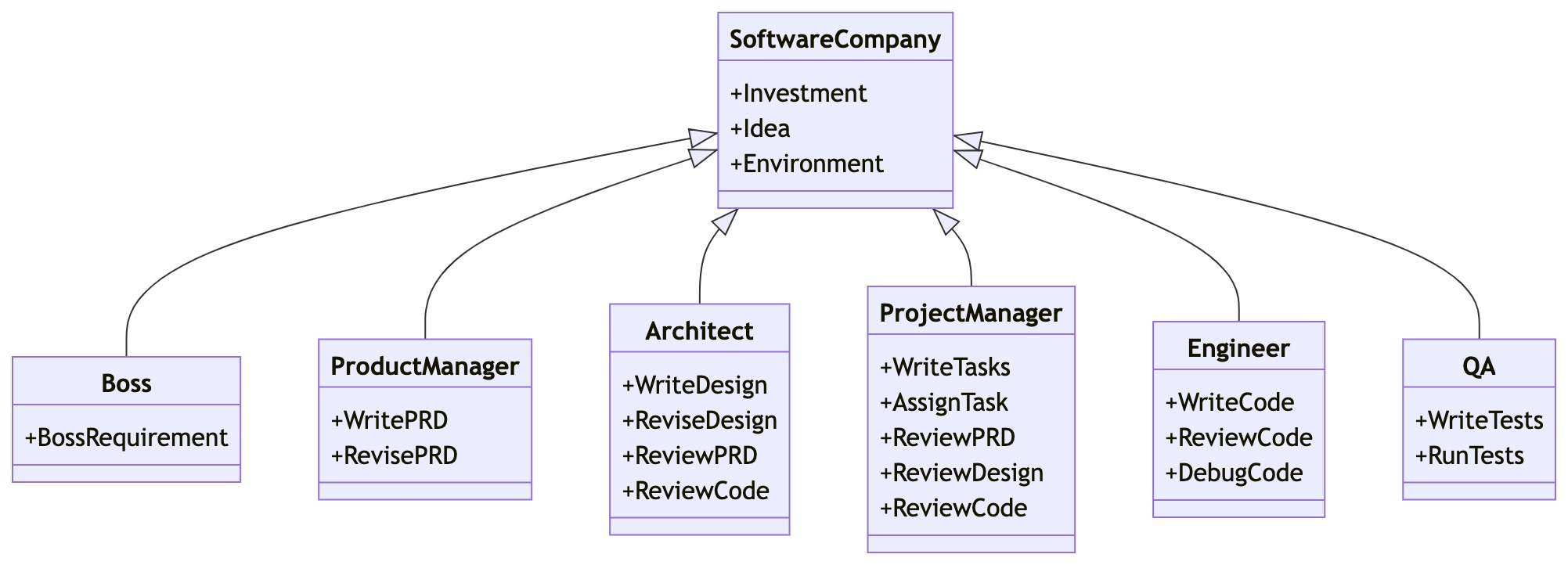
I am following agentic AI with interest. In The Memo edition 5/Aug/2023, we looked at Amazon Bedrock agents. Now, a new collaboration between researchers at several Chinese universities, the University of Pennsylvania. and the University of California, Berkeley, is groundbreaking.
MetaGPT leverages the assembly line paradigm to assign diverse roles to various agents, thereby establishing a framework that can effectively and cohesively deconstruct complex multi-agent collaborative problems.
Read the paper: https://arxiv.org/abs/2308.00352
View the repo: https://github.com/geekan/metagpt
Anthropic gets another $100M from SKT (13/Aug/2023)
Anthropic, an artificial intelligence startup co-founded by former OpenAI leaders, will receive $100 million in funding from one of the biggest mobile carriers in South Korea, SK Telecom (SKT), the telco company announced on Sunday.
The funding news comes three months after Anthropic raised $450 million in its Series C funding round led by Spark Capital in May. Prior to the latest investment, SKT participated in the Series C round through its venture capital arm, SK Telecom Venture Capital (SKTVC). Just last month, Germany-based software company SAP also invested in Anthropic.
Five years of GPT progress (Mar/2023)
Here’s a summary of LLMs from 2018-2023 by another writer. If you’ve always wanted to read more about this stuff but hear it in a different voice to mine(!), this is the summary to read.
Read more: https://finbarr.ca/five-years-of-gpt-progress/
OpenAI acqui-hires Global Illumination (16/Aug/2023)
I was getting a bit concerned that Anthropic and Google have a lot more brain power than OpenAI. But, as usual, OpenAI has come through. Eight new scientists have been brought into the fold, from a gaming company called Global Illumination.
Read more: https://openai.com/blog/openai-acquires-global-illumination
Boston Dynamics Spot working at Ontario Power Generation (26/Jul2023)
[Spot provides] a much more streamlined approach where the robot is able to trip [a circuit breaker] on its own, place the tool in on its own, and to start the entire racking out process fully autonomously. In terms of practicality, for us to go do this in the field, it's now a lot simpler…
Watch the video (link):
Claude 2 & Consciousness (8/Aug/2023)
Dario Amodei (on Claude being conscious):
One thing I'll tell you is I used to think that we didn't have to worry about this at all until models were operating in rich environments, like not necessarily embodied, but they needed to have a reward function and have a long lived experience. I still think that might be the case, but the more we've looked at these language models and particularly looked inside them to see things like induction heads, a lot of the cognitive machinery that you would need for active agents already seems present in the base language models.
So I'm not quite as sure as I was before that we're missing enough of the things that you would need. I think today's models just probably aren't smart enough that we should worry about this too much but I'm not 100% sure about this, and I do think in a year or two, this might be a very real concern.
Let's say we discover that I should care about Claude’s experience as much as I should care about a dog or a monkey or something. I would be kind of worried. I don't know if their experience is positive or negative. Unsettlingly I also don't know I wouldn't know if any intervention that we made was more likely to make Claude have a positive versus negative experience versus not having one.
Read the transcript or watch the video.
Policy
The AI rules that US policymakers are considering, explained (1/Aug/2023)
This is a massive and high-quality literature review (4,200 words + many links) by Vox’s senior correspondent and head writer Dylan Matthews. It explores four key areas:
Rules: New regulations and laws for individuals and companies training AI models, building or selling chips used for AI training, and/or using AI models in their business
Institutions: New government agencies or international organizations that can implement and enforce these new regulations and laws
Money: Additional funding for research, either to expand AI capabilities or to ensure safety
People: Expanded high-skilled immigration and increased education funding to build out a workforce that can build and control AI
Read more: https://www.vox.com/future-perfect/23775650/ai-regulation-openai-gpt-anthropic-midjourney-stable
Pentagon establishes Task Force Lima to study generative AI issues (11/Aug/2023)
WASHINGTON — The U.S. Defense Department has created a task force to evaluate and guide the application of generative artificial intelligence for national security purposes, amid an explosion of public interest in the technology.
Task Force Lima falls under the purview of the department’s Chief Digital and AI Office, or CDAO, itself a little more than a year old. Other defense and intelligence community organizations will participate, according to an Aug. 10 memo signed by Deputy Defense Secretary Kathleen Hicks.
Download the memo from Washington as featured here in The Memo(!) or archive below (PDF).
Toys to Play With
Worldwide autonomous vehicle rollout details (2023)
This website tracks global robotaxi rollout. We (Autoura) run a digital experience platform that incorporates robotaxis within tourism, leisure & hospitality experiences and we need to track: where robotaxis are (cities & service areas), where they are expected to be, consumer prices, vehicle capabilities.
Take a look (text only): https://rollout.autoura.com/
DoctorGPT using Llama 2 7B (12/Aug/2023)
DoctorGPT is a Large Language Model that can pass the US Medical Licensing Exam. This is an open-source project with a mission to provide everyone their own private doctor. DoctorGPT is a version of Meta's Llama2 7 billion parameter Large Language Model that was fine-tuned on a Medical Dialogue Dataset, then further improved using Reinforcement Learning & Constitutional AI. Since the model is only 3 Gigabytes in size, it fits on any local device, so there is no need to pay an API to use it. It's free, made for offline usage which preserves patient confidentiality, and it's available on iOS, Android, and Web.
Try it: https://github.com/llSourcell/DoctorGPT
Gamma: Powerpoint by AI (2023)
Try it: https://gamma.app/
Harpa.ai for YouTube summaries (Aug/2023)

I’ve noticed that some very kind video viewers and commenters are using Harpa.ai to summarize my newer videos, and then they dump that out as a comment. I’ve not used it directly, but the output is clear and concise. Thanks to @DragonFlameAce and others.
Try it: https://harpa.ai/case/chatgpt-for-youtube
Text-to-song with Suno.ai (Aug/2023)
Our AI models enable creatives and developers to generate hyper-realistic speech, music and sound effects — powering personalized, interactive and fun experiences across gaming, social media, entertainment and more.
Try it: https://www.suno.ai/
Watch my video using GPT-4 to write lyrics about Leta AI (link):
Interview with Financial Sense (15/Aug/2023)
Another deep dive interview with financial expert Cris Sheridan; updates on PaLM 2, Llama 2, 1X NEO, and more.
Watch the video (link):
Flashback
Integrated AI: Dataset quality vs quantity via bonum (GPT-4 and beyond) (Jun/2021)
After an interesting email from a reader, I was reminded of this old article about curating high-quality datasets for training models. I no longer believe that this is the best course of action, instead preferring to train these models with ‘everything,’ and then fine-tuning or even steering with ‘constitutional AI’ (or better) to align it with global humanity and/or a more localised context. (Much like we’d raise a child.)
Read the article: https://lifearchitect.ai/bonum
Next
I’d like to invite you to the next roundtable for full subscribers. This is a video call in an informal setting, an opportunity for you to talk about anything AI, and to meet other paid readers.
This is a roundtable for all participants, not a Q&A; I will not be ‘driving’ this meeting, and even though the legendary Harvey Castro MD will be joining us, he will also be sitting back a little. The next roundtable will be:
Life Architect - The Memo - Roundtable #2 with Harvey Castro
Saturday 26/Aug/2023 at 5PM Los Angeles
Saturday 26/Aug/2023 at 8PM New York
Sunday 27/Aug/2023 at 8AM Perth (primary/reference time zone)
or check your timezone.
You don’t need to do anything for this; there’s no registration or forms to fill in, I don’t want your email, you don’t even need to turn on your camera or give your real name!
All my very best,
Alan
LifeArchitect.ai