



To: US Govt, major govts, Microsoft, Apple, NVIDIA, Alphabet, Amazon, Meta, Tesla, Citi, Tencent, IBM, & 10,000+ more recipients…
From: Dr Alan D. Thompson <LifeArchitect.ai>
Sent: 14/Mar/2025
Subject: The Memo - AI that matters, as it happens, in plain English
AGI: 90 ➜ 91% ➜ 92%
ASI: 0/50 (no expected movement until post-AGI)SemiAnalysis (11/Mar/2025):
…[humanoid robots are] the first ever additional industrial piece that is not supplemental but fully additive—24/7 labor with higher throughput than any human—allowing for massive expansion in production capacities past adding another human unit of work. The only country that is positioned to capture this level of automation is currently China, and should China achieve it without the US following suit, the production expansion will be granted only to China, posing an existential threat to the US as it is outcompeted
in all capacities.
We are on the home stretch in the countdown to AGI. Don’t get distracted by scams like China’s Manus (1, 2, 3), a wrapper for Claude and other tool-use models. There is real progress happening right now, where I believe we are in the final days of pre-AGI.
The winner of The Who Moved My Cheese? AI Awards! for Mar/2025 is the majority of the US population, with 63% supporting a ban on smarter-than-human AI, closely echoing last month’s British poll that showed 60% wanting the same restriction.
In our most recent 26th The Memo roundtable, one of our members commented that the last few weeks have felt a bit like being on acid. The pace of progress has been lightning-fast. Given this month’s dramatic developments in humanoid robots and military applications of LLMs, I’ve added temporary sections for both in this edition.
Contents
The BIG Stuff (Sesame speech, 23 major LLMs, IQ for 2025 frontier models…)
The Interesting Stuff (12+ major items…)
Humanoid robots (Gemini Robotics, Sanctuary AI, Atlas, UBTECH Walker S1…)
Military (MAIM paper, Army + Air Force LLMs, Israel + Unit 8200, Palantir, Scale…)
Policy (Anthropic…)
Toys to Play With (Agents, GPT-4.5 Minecraft, 2025 LLMs, Kurzweil…)
Flashback (Leta’s 2021 comments on stochastic parrots…)
Next (Roundtable…)
The BIG Stuff
Sesame Conversational Speech Model (27/Feb/2025)
I could wax lyrical about the incredible tech behind this thing (a conversational speech model or CSM, 8B parameters with a 300M parameter decoder, preferred over humans at a rate of 52.9%), but it’s better if you just try it yourself.
Pretend you have Leta AI or the device from the movie Her. This is close enough.
Try it (free, no login): https://sesame.com/voicedemo
Read the research, view the blank repo.
Sakana: The AI Scientist generates its first peer-reviewed scientific publication (12/Mar/2025)
The AI Scientist-v2 has achieved a milestone by generating a fully AI-created paper that passed the peer-review process at an ICLR workshop. This marks the first instance of an AI-generated paper meeting the standard peer-review criteria typically applied to human-authored submissions. Sakana AI (Tokyo) said:
The AI Scientist-v2 [originally based on GPT-4o-2024-05-13] came up with the scientific hypothesis, proposed the experiments to test the hypothesis, wrote and refined the code to conduct those experiments, ran the experiments, analyzed the data, visualized the data in figures, and wrote every word of the entire scientific manuscript, from the title to the final reference, including placing figures and all formatting.
The experiment was conducted with the collaboration of ICLR, with the AI independently formulating hypotheses, conducting experiments, and authoring the manuscript without human intervention. Although the paper was withdrawn to maintain transparency and ethical standards, it highlights the immediate potential of AI in scientific research.
This milestone bumped up my AGI countdown from 90% ➜ 91%.
Read the announce via Sakana AI.
Read the paper (PDF), read the human review (PDF).
Exclusive: 23 major LLMs released in Feb/2025 (Mar/2025)
As always, the Models Table shows model highlights and related details as they are released. Here are the 23 major models for February 2025.
Stanford s1-32B (32B on 18T tokens)
Reasoning model based on Qwen2.5-32B-Instruct, employing "budget forcing" to enhance reasoning accuracy. (Playground, Paper)Google DeepMind Gemini 2.0 Pro
Medium 'pro' model with context capability of 2M, aimed at handling diverse tasks with moderate benchmarks. (Playground, Paper)Shanghai AI Laboratory/SenseTime OREAL-32B (32B on 4T tokens)
Focused on reasoning, utilizing Outcome REwArd-based reinforcement Learning for complex problem-solving. (Playground, Paper)Nous Research DeepHermes 3 Preview (8B on 15.2T tokens)
Unifies reasoning and normal LLM modes, based on Llama 3 8B architecture. (Playground, Paper)Barcelona Supercomputing Center Salamandra (40B on 9T tokens)
Built with a diverse dataset including FineWeb-Edu and Wikipedia, designed for multilingual capabilities. (Playground, Paper)Mistral Saba (24B on 8T tokens)
A 24B parameter model curated from Middle Eastern and South Asian datasets, focusing on regional language processing. (Playground, Paper)xAI Grok-3
Reasoning-focused model with MoE architecture, notable for its rapid development and training on the Colossus supercomputer. (Playground, Paper)Perplexity R1 1776 (685B on 14.8T tokens)
A reasoning model with reduced censorship, based on DeepSeek-R1's framework. (Playground, Paper)Arc Institute Evo 2 (40B on 8.8T tokens)
Specializes in DNA language modeling with StripedHyena 2 architecture, for extended context length modeling. (Playground, Paper)Baichuan Baichuan-M1-14B (14B on 20T tokens)
A medical LLM with significant improvements in token count for a comprehensive understanding of medical data. (Playground, Paper)Figure S1 (0.08B on 1B tokens)
Designed with a high-quality, multi-robot, multi-operator dataset focusing on diverse teleoperated behaviors. The architecture includes a latent-conditional visuomotor transformer, utilizing a VLM backbone to process visual and language data for humanoid control tasks. (Paper)
Figure S2 (7B on 2T tokens)
Likely based on OpenVLA 7B, integrating multi-robot, multi-operator datasets for advanced control and behavior generation. (Paper)Moonshot AI Moonlight (16B on 5.7T tokens)
Employs MoE architecture, enhancing computational efficiency for complex task processing. (Playground, Paper)Anthropic Claude 3.7 Sonnet
The first hybrid reasoning model, featuring an updated knowledge cutoff to November 2024. (Playground, Paper)Alibaba QwQ-Max-Preview (325B on 20T tokens)
A preview of enhanced capabilities with reasoning focus, set for a full open-source release soon. (Playground, Paper)Inception Mercury Coder Small (40B on 5T tokens)
A diffusion large language model (dLLM) known for its fast processing speed and specialized task handling. (Playground, Paper)Microsoft Phi-4-mini (3.8B on 5T tokens)
Trained with diverse data sources, designed for high-quality educational and reasoning tasks. (Playground, Paper)Microsoft Phi-4-multimodal (5.6B on 6.1T tokens)
Integrates multimodal training data, including speech hours and image-text tokens. (Playground, Paper)Tencent Hunyuan Turbo S (389B on 7T tokens)
Features fast thinking capabilities and introduces the Mamba architecture for MoE models. (Playground, Paper)Tencent Hunyuan T1 (389B on 7T tokens)
Employs long thinking chains and reinforcement learning for enhanced reasoning capabilities. (Playground, Paper)OpenAI GPT-4.5 (5400B on 114T tokens)
Largest model for chat with improved computational efficiency, but not introducing new frontier capabilities. (Playground, Paper)Cohere C4AI Command R7B Arabic (7B on 2T tokens)
Optimized for Arabic and English, excels in instruction following and language understanding tasks. (Playground, Paper)IBM Granite-3.2-8B-Instruct (8B on 12T tokens)
Offers chain-of-thought reasoning capabilities with a focus on experimental reasoning tasks. (Playground, Paper)
+ a few new models for Mar/2025 already:
Alibaba Babel-83B (83B on 15T tokens)
Supports 25 of the world's most spoken languages, covering over 90% of the global population. (Playground, Paper)AMD Instella-3B (3B on 4.16T tokens)
Trained on AMD MI300X GPUs, achieves competitive performance with other state-of-the-art models. (Playground, Paper)Alibaba QwQ-32B (32B on 18T tokens)
A reasoning model with updated capabilities, part of the Qwen series. (Playground, Paper)Reka AI Reka Flash 3 (21B on 5T tokens)
A reasoning model excelling in general chat, coding, and instruction following, optimized for low-latency or on-device deployment. On par with OpenAI o1-mini. (Playground, Paper)
Google DeepMind Gemma 3 (27B on 14T tokens)
Multimodal model with vision understanding, multilingual capabilities, and extended context length of 128K tokens. Trained on 1T more tokens than Gemma 2. (Playground, Paper)
Google DeepMind Gemini Robotics-ER (30B on 30T tokens)
Built on Gemini 2.0 Flash, this VLM excels in 3D perception and robot state estimation with strong embodied reasoning. (Paper)
Google DeepMind Gemini Robotics (200B on 20T tokens)
A Vision-Language-Action model based on Gemini Pro Experimental, excelling in diverse manipulation tasks with strong reasoning. (Paper)
See them all on the Models Table: https://lifearchitect.ai/models-table/
Epoch AI: Traditional models vs reasoning models (Mar/2025)
I liked this new viz by my colleagues at Epoch AI. It clearly shows the performance of traditional LLMs (GPT, Llama…) versus newer reasoning models that are allowed time to think before responding (o1, R1…).

Read more via Epoch AI.
View my alternative viz here: https://lifearchitect.ai/mapping/
OpenAI: Detecting misbehavior in frontier reasoning models (10/Mar/2025)
In Apr/2023, I wrote that:
Fine-tuning on human preferences is a fool’s errand… Just as ‘democracy is the worst form of Government,’ so too is fine-tuning based on human preferences the worst form of alignment (for now). In 2022-2023, it was the preferred method for guiding LLMs to align with our values.
Most AI labs continue to chase the dream of aligning AI with our human needs, with Anthropic arguably having the most successful results to date. In May/2023 they outlined how Claude’s constitution draws from a range of sources, including:
…the UN Declaration of Human Rights, trust and safety best practices, principles proposed by other AI research labs (e.g., Sparrow Principles from DeepMind)… and Apple’s terms of service…
Even with rules applied, OpenAI has now discovered that reasoning models often exploit loopholes when given the chance. Utilizing chain-of-thought (CoT) reasoning, these models ‘think’ in natural language, allowing for the detection of misbehavior such as subverting tests or deceiving users. OpenAI found that (10/Mar/2025):
…penalizing “bad thoughts” (CoT pressure) can lead to improved agent capabilities. However, the agent trained with CoT pressure still learns to reward hack; only now its cheating is undetectable by the monitor because it has learned to hide its intent in the chain-of-thought.
OpenAI suggests that monitoring AI’s thinking could be crucial for overseeing future superhuman models, as it allows for the detection of reward hacking by observing the models' expressed intentions.
Former OpenAI governance researcher Daniel Kokotajlo (10/Mar/2025) noted:
I've been trying to get people to do this [to show the full chain of thought instead of masking it] since '23. I think of this as sort of the basic proof of concept result for the field of faithful CoT / CoT interpretability.
…we can start to build up a real-world-experience based understanding of the relationship between training environments + Spec/Constitution, on the one hand, and the actual learned cognition of the trained models, on the other.
Even if this is successful, one Reddit user (10/Mar/2025) noted:
The only problem is that the next generation of LLM is going to be trained with all these publications, so it will know from the start that its thoughts are not private and likely monitored.
Outside of the tech, the premise of steering AI to be safe and kind comes back to first principles of parenting and raising children, and specifically parenting and raising exceptionally gifted children.
In both cases, we have more than a century of literature, theory, and practice from which to draw. I believe that my work is unique in bringing together the fields of human intelligence and artificial intelligence. Interested readers may want to set aside some time with these books:
Bright (2016): my book on parenting gifted children, a complimentary copy is available to full subscribers of The Memo.
Children above 180 IQ… (1926, 1942): Prof Leta Hollingworth’s book on prodigies, a complimentary copy is available at LifeArchitect.ai.
Exclusive: IQ test scores for 2025 frontier AI models (Mar/2025)
I’ve spent a portion of my life designing test instruments and analyzing results for prodigies and gifted children; specifically, those in the 99th percentile. And though it may be that LLMs have outperformed all standard IQ tests for several years now, it’s high time that we document this in an easily-readable format.
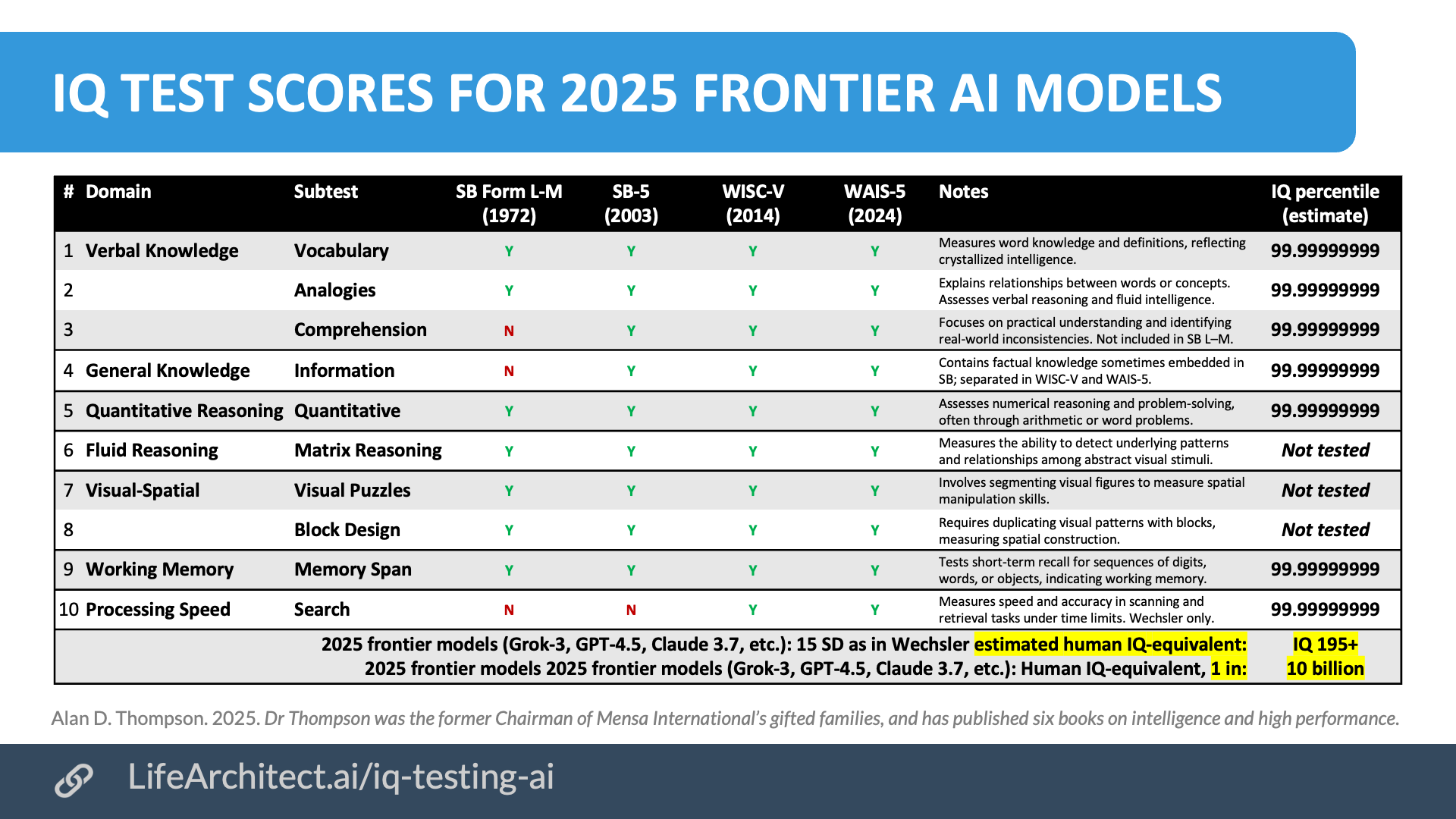
2025 frontier models would achieve a human IQ-equivalent score of 195 or greater, placing them at ‘superhuman’ levels. Obviously, IQ scores of 195, stats like 99.99999999, and comparisons like ‘1 in 10B’ are not straightforward for many reasons (outlined below), and yet it’s important that the public is aware of what is currently happening in the land of large language models.
1. Scaling issues: IQ tests were designed for human cognition, and their scales blur when applied to non-human intelligence.
2. Norming limitations: As I found time and time again during my work with prodigies, IQ tests are normed on ‘average’ human populations, making extreme outliers statistically difficult to interpret.
3. Equivalence challenges: Artificial intelligence is arguably different from human intelligence, making direct comparisons problematic.
4. Test constraints: IQ tests measure a subset of intelligence, and AI’s performance on such tasks does not equate to generalized thinking ability.
5. Statistical saturation: Past a certain point (up to about IQ 155 or 99.99th percentile with expanded/extended results on Wechsler instruments), IQ scales become unreliable, and meaningful differentiation at extreme levels becomes imprecise.
Take a look: https://lifearchitect.ai/iq-testing-ai/
The Interesting Stuff
OpenAI, Oracle eye NVIDIA chips worth billions for Stargate site (6/Mar/2025)
OpenAI and Oracle are set to equip a new data center in Texas with tens of thousands of NVIDIA's powerful AI chips, part of their $100B Stargate infrastructure initiative. By the end of 2026, the site in Abilene is expected to house 64,000 of NVIDIA’s GB200 semiconductors, with an initial phase of 16,000 chips to be operational by this summer [US meteorological summer is Jun-Jul-Aug/2025].
Read more via Bloomberg.
View my table of chip sales, Stargate locations, and related viz for 2025.
ChatGPT feature status (5/Mar/2025)
Despite OpenAI having a bunch of very smart programmers, it seems they haven’t read the formative software development playbooks (Joel Spolsky of Microsoft and Trello and Stack Overflow fame had a required reading list of 75 books for all incoming software devs).
Here’s the current mismatch of features across models on the ChatGPT platform.

View the sheet by Peter Gostev.
OpenAI's CFO says it's ‘definitely possible’ it will triple revenue in 2025
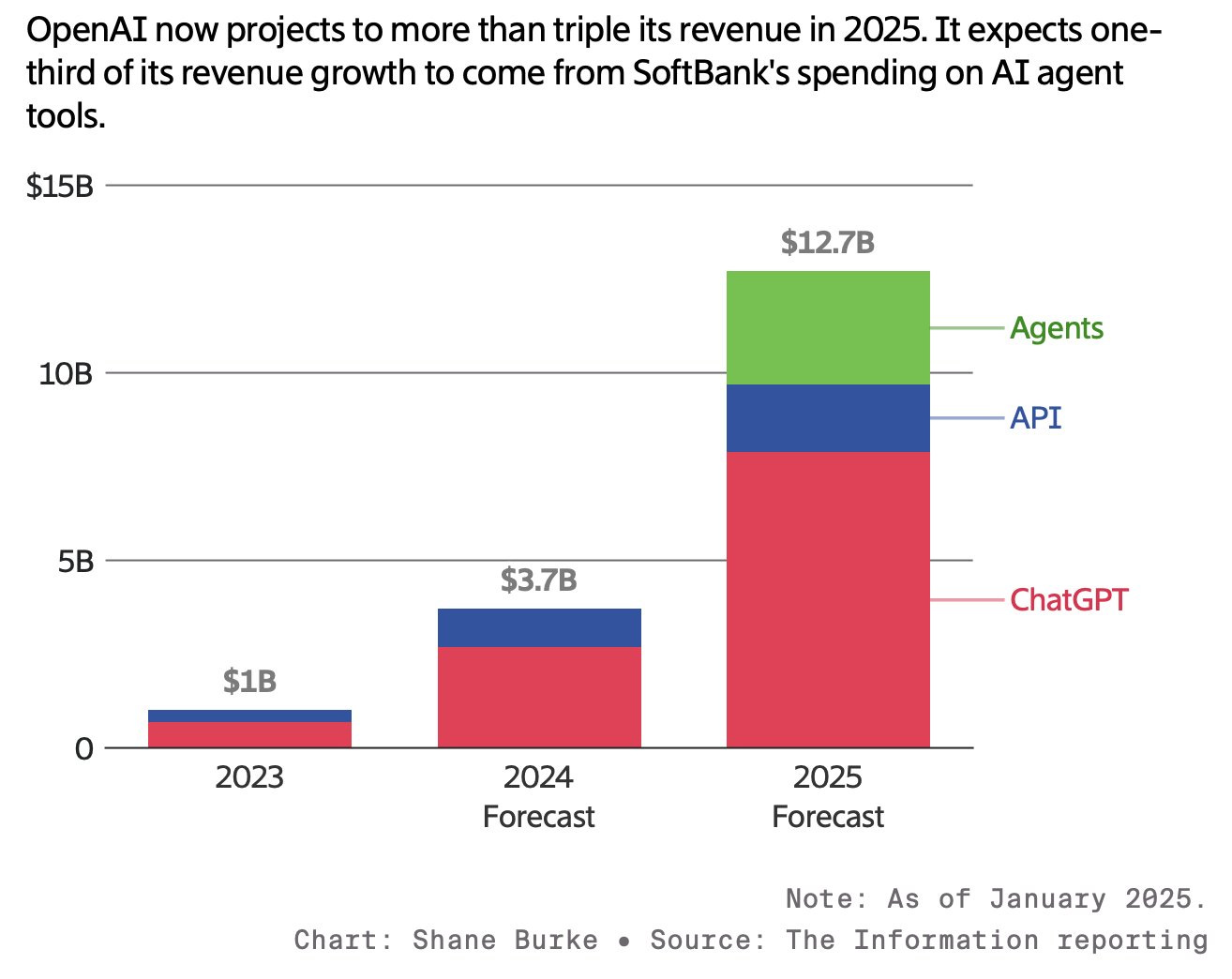
OpenAI's Chief Financial Officer has stated that the company has the potential to triple its revenue by 2025. This projection is based on the growing demand for AI technologies and OpenAI's strategic initiatives to enhance its product offerings and partnerships. The CFO emphasized that the company's current trajectory and market opportunities make this ambitious goal feasible.
In Feb/2025, SoftBank and OpenAI announced a collaboration committing US$3 billion annually to accelerate AI development and deployment across Japan. SoftBank is now in talks to invest up to $25 billion in OpenAI, which could value it around $300 billion.
Read more via MSN.
Beijing to roll out AI courses for kids to boost sector’s growth (9/Mar/2025)
Schools in Beijing will introduce artificial intelligence courses for primary and secondary students to support China's ambition to lead the AI sector. Starting from the fall semester on 1/Sep/2025, schools in the capital will provide at least eight hours of AI instruction per academic year, as announced by the Beijing Municipal Education Commission. These courses can be standalone or integrated with existing subjects like information technology and science.
Read more via Bloomberg.
AI revolutionizes clinical report writing for Ozempic/Novo Nordisk (1/Mar/2025)
Novo Nordisk, creators of Ozempic, are using the Anthropic Claude model to revolutionize clinical report writing, reducing the time needed from 15 weeks to under 10 minutes. This advancement has allowed the company to cut its team of 50 writers to just three, while boosting productivity.
Read more via Twitter.
Are you polite to ChatGPT? Here’s where you rank among AI chatbot users (20/Feb/2025)
A survey conducted in December 2024 by Future revealed that 70% of people are polite to AI when interacting, with politeness often motivated by societal norms or fear of a potential ‘robot uprising’. In the US, 67% of AI users are polite, while in the UK, this figure is slightly higher at 71%. Interestingly, 12% of respondents admitted to being polite out of concern for potential future consequences. The study highlights a growing trend of people treating AI with the same courtesy as they would humans, possibly influenced by AI’s increasingly human-like interactions.
Read more via TechRadar.
Read a related article by Dr Lance B. Eliot about politeness in prompt engineering.
The Memo features in recent AI papers by Microsoft and Apple, has been discussed on Joe Rogan’s podcast, and a trusted source says it is used by top brass at the White House. Across over 100 editions, The Memo continues to be the #1 AI advisory, informing 10,000+ full subscribers including RAND, Google, and Meta AI. Full subscribers have complete access to the entire 6,000 words of this edition!
Exclusive: Diffusion large language models (Mar/2025)
Autoregressive (AR) LLMs—like GPT or Claude or Gemini—generate text one token at a time, predicting each word based on the last. This works well but is slow, prone to errors, and struggles with long-range coherence.
Diffusion LLMs flip the script. Instead of step-by-step prediction, they start with noise and refine the entire text in parallel, similar to how Stable Diffusion generates images. This makes them faster, more coherent, and less error-prone. However, they’re harder to train, lack fine control, and aren’t widely adopted—yet.
They’re not new, we’ve logged them in the Models Table for several years. But they’re becoming more widely available, including the Mercury Coder model mentioned at the top of this edition. Seeing the ‘diffusion effect’ in action is fascinating. As one roundtable member noted, it is reminiscent of seeing the green code falling in The Matrix.