


The Memo - 12/Jul/2025
Moonshot Kimi K2 1T on 15.5T, AWS Project Rainier, GPT-4x and o scores, and much more!

To: US Govt, major govts, Microsoft, Apple, NVIDIA, Alphabet, Amazon, Meta, Tesla, Citi, Tencent, IBM, & 10,000+ more recipients…
From: Dr Alan D. Thompson <LifeArchitect.ai>
Sent: 12/Jul/2025
Subject: The Memo - AI that matters, as it happens, in plain English
AGI: 94%
ASI: 0/50 (no expected movement until post-AGI)Senior VP of a multibillion-dollar corporation (Jun/2025, private audience):
’We’re no longer getting incremental funding for hiring people, we’re getting incremental funding for Devin AI licences [pricing=US$6,000/year in 2025].’
The early winner of The Who Moved My Cheese? AI Awards! for Jul/2025 is the Australian Nursing & Midwifery Journal (‘AI will never be able to replace the critical thinking skills and adaptability that nurses demonstrate every day on their jobs.’).
If you think there was a bit of a lull in AI releases over the last ~30 days, you’d be right. OpenAI recently closed its doors for a week (29/Jun/2025) and not much happened between Gemini 2.5 Pro 06-05 (5/Jun/2025) and Grok 4 on 9/Jul/2025. Expect to see more major releases shortly.
The next roundtable is in ~24 hours from this email, all full subscribers have a standing invitation, and details are at the end of this edition.
Contents
The BIG Stuff (Kimi K2, GPT-4x and o scores, 97% students, Grok 4…)
The Interesting Stuff (Don’t talk about alignment, robots, talent swap, OAI browser…)
Policy (Russian Shahed MS001 and GPT, Huawei LLM whistleblower, Anthropic…)
Toys to Play With (New text-to-image quiz, Imagen 4 Ultra, Claude time…)
Things I’ve Been Thinking About (Humanity’s apocalypse fetish…)
Next (AGI, roundtable…)
The BIG Stuff
Kimi K2 is the new state-of-the-art open source model (12/Jul/2025)
Kimi K2 is our latest Mixture-of-Experts model with 32 billion activated parameters and 1 trillion total parameters… Kimi K2 was pre-trained on 15.5T tokens using MuonClip with zero training spike, demonstrating MuonClip as a robust solution for stable, large-scale LLM training.
Kimi K2 is about twice the size of DeepSeek-R1. At 1T MoE on 15.5T tokens, K2 is one of the largest open source models to date (BAAI’s Tele-FM is 1T dense on 15.7T tokens).
MMLU=89.5, MMLU-Pro=81.1, GPQA=75.1, HLE=4.7
Read the announce: https://moonshotai.github.io/Kimi-K2/
Download the weights: https://huggingface.co/moonshotai/Kimi-K2-Instruct
Sidenote: At standard 8-bit quantization, I estimate you’d need ~13× A100 or H100 GPUs (1TB model spread across several GPUs with 80GB RAM each). At 2025 retail price of around US$40k per GPU (rough estimate due to demand), that’d be a half million dollar investment to run this model on your own hardware.
See it on the Models Table: https://lifearchitect.ai/models-table/
The Memo features in recent AI papers by Microsoft and Apple, has been discussed on Joe Rogan’s podcast, and a trusted source says it is used by top brass at the White House. Across over 100 editions, The Memo continues to be the #1 AI advisory, informing 10,000+ full subscribers including RAND, Google, and Meta AI. Full subscribers have complete access to all 30+ AI analysis items in this edition!
Exclusive: The GPT-4x and o Model Family: Varied Intelligence Scores 2024–2025
Big numbers roll off the human understanding like water off a duck’s back. So let’s look at them in pictures instead. Using official GPQA score data from OpenAI’s simple evals page, here’s my latest visualization of the current OpenAI models in mid-2025 by GPQA score:
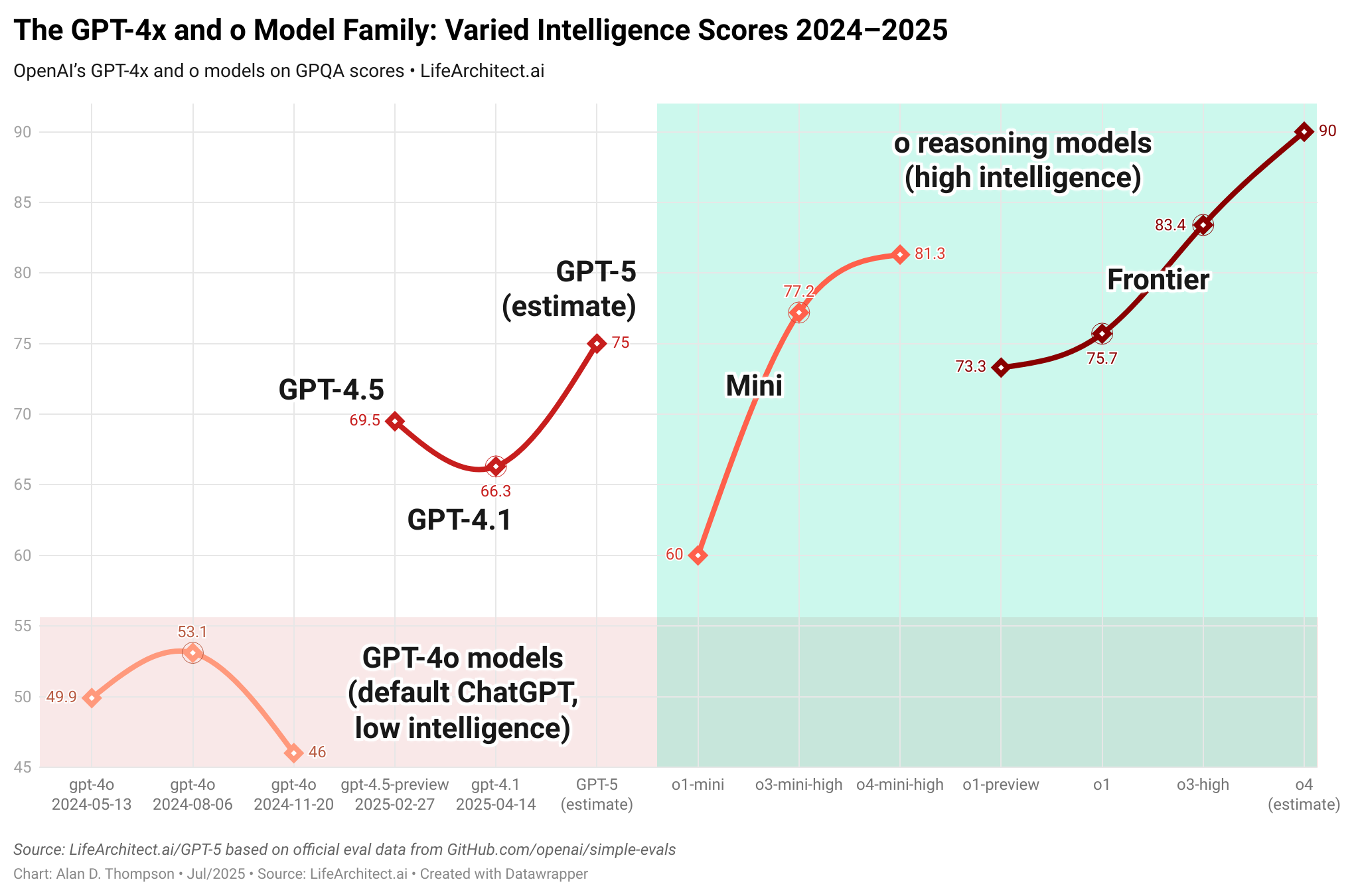
Takeaways:
Out of necessity, the default ChatGPT model in mid-2025 (gpt-4o-2024-11-20) is comparatively low intelligence. The decision here was based on latency and availability (quick responses and consistent access) while serving LLMs to nearly a billion users: smaller and faster (and subsequently dumber) is more cost-effective and reliable.
The default GPT-4o model (Nov/2024) was even significantly dumbed down compared to the previous GPT-4o model (Aug/2024). Again, all in the name of throughput and availability.
Selecting the GPT-4.1 model in the ChatGPT interface is usually a good idea (if you don’t need image generation), as it is significantly better than the default ChatGPT model, while still being fast.
The breakthrough ‘aha!’ discovery of reasoning models (starting with o1 in late 2024) was significant. Note the jump in performance compared to traditional models on the left (at the temporary expense of speed).
There’s nowhere left to go at the top. The creators of the GPQA test estimated the proportion of questions that have uncontroversially correct answers to be only 74% on GPQA Extended (Nov/2023), and higher for the filtered GPQA Main and GPQA Diamond (I estimate these to be around 90%). After that, we have to rely on Humanity’s Last Exam for testing. And after that… there’s nothing else! We’ll be inside superhuman performance and ASI.
Read more about ASI: https://lifearchitect.ai/asi/
Read more about the big benchmarks: https://lifearchitect.ai/mapping/
Read more about GPT-5: https://lifearchitect.ai/gpt-5/
97% of students turn to AI for homework, essays, and college apps (5/Jul/2025)