

The Memo - 5/Jul/2024
The Memo - 5/Jul/2024
DCLM-Pool 240T, Baidu ERNIE 4.0 Turbo, ChatGPT 'delves', and much more!

To: US Govt, major govts, Microsoft, Apple, NVIDIA, Alphabet, Amazon, Meta, Tesla, Citi, Tencent, IBM, & 10,000+ more recipients…
From: Dr Alan D. Thompson <LifeArchitect.ai>
Sent: 5/Jul/2024
Subject: The Memo - AI that matters, as it happens, in plain English
AGI: 75%OpenAI CEO (27/Jun/2024):
”There’s tonnes of wonderful things… What are our lives going to be like when it's not just that the computer understands us, gets to know us, and helps us do these things? We can say, 'Hey computer, discover all of physics,' and it can go off and do that. What does it mean when we can say, 'Hey, start and run a great company,' and it can go off and do that? That's a big change."
July 2024! We’re in the second half of the year already. The first half—as presented in my mid-year report—was spectacular.

There’s been a bit of talk about an ‘AI downturn’. If the media can’t see the immense ‘economic benefits’ already apparent, perhaps it is to be expected from that industry. Some are saying we are in the ‘trough of disillusionment’ for AI, and while I like Gartner, their incessant need to map their ‘hype cycle’ graphic (wiki) to anything and everything is… justified by their business model.
There is no AI hype cycle. Like humanity, AI is much more than a tool, a productivity enhancement, an automation, or even an industry. We can’t map ‘evolution’ or ‘imagination’ to a hype cycle. Gartner and Goldman Sachs may want to stick to the knitting.
Contents
The BIG Stuff (Sonnet details, humor…)
The Interesting Stuff (first major app written with AI, acquisitions, dataset…)
Policy (ChatGPT publishing papers, IATSE…)
Toys to Play With (Free chat, running 1.5B/70B/405B models locally, UBI show…)
Flashback (Roadmap…)
Next (Roundtable…)
The BIG Stuff
Claude 3.5 Sonnet details (Jun/2024)
The Claude 3.5 Sonnet release has been significant, and new emergent properties are still being discovered. We first covered this model within a few hours of launch in The Memo edition 21/Jun/2024.

There is still no official information on Claude 3.5 Sonnet: no paper, no technical note, and no model card. There is a blog post with some benchmarks and pretty pictures, and that’s it.
In 2020, AI labs were proud to release hundred-page academic papers about their models. By 2023, this had shrunk to releasing short ‘technical notes’ or single-page ‘model cards’. Now—apparently—we have to trawl through mainstream media pieces to get just a glimpse of how models were trained.
Michael Gerstenhaber, head of product at Anthropic, was interviewed by two outlets in particular where he provided a little more detail on Claude 3.5 Sonnet. For Wired:
Claude 3.5 Sonnet model is larger than its predecessor but draws much of its new competence from innovations in training. For example, the model was given feedback designed to improve its logical reasoning skills. — 20/Jun/2024
For TechCrunch:
The improvements are the result of architectural tweaks and new training data, including AI-generated data. Which data specifically? Gerstenhaber wouldn’t disclose, but he implied that Claude 3.5 Sonnet draws much of its strength from these training sets. — 20/Jun/2024
I’ve been using the incredible Claude 3.5 Sonnet Artifacts component, and it really is amazing to see in real time (as we explored in the recent roundtable). Take a look at my video (link) and generated web page at https://lifearchitect.ai/distractions
I’ve also taken the time to highlight the full 2,800-word system prompt for Claude 3.5 Sonnet Artifacts. The biggest innovation here is Anthropic’s ‘<antThinking>’ mechanism which allows Claude 3.5 to privately think and reason step-by-step, also known as chain-of-thought (CoT) reasoning.
Anthropic has documented the older <thinking> tag here: https://docs.anthropic.com/en/docs/build-with-claude/tool-use#chain-of-thought
In early July 2024, other researchers flagged the new antThinking hidden mechanism here and here.
Take a look at the Claude 3.5 Sonnet Artifacts system prompt.
How funny is ChatGPT? A comparison of human- and A.I.-produced jokes (3/Jul/2024)
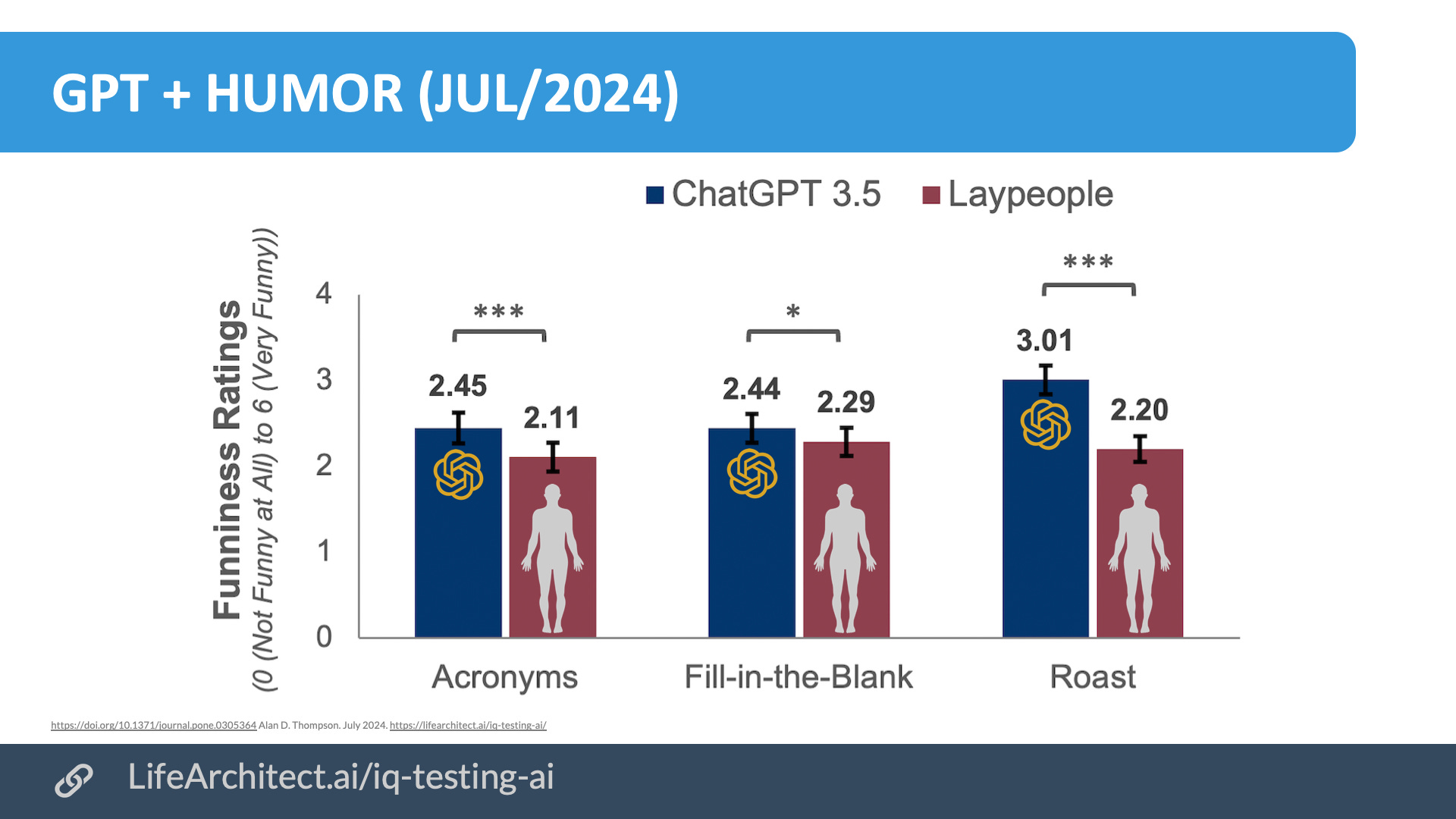
Last year I had a difference of opinion with Prof Jeremy Howard during a private discussion where I told ABC that AI would outperform humans in standup comedy (joke telling). Turns out I was qualitatively and quantitatively correct. A new study systematically tested ChatGPT 3.5’s humor production abilities against human participants. Results showed that ChatGPT 3.5-produced jokes were rated as equally funny or funnier than human-produced jokes, regardless of the comedic task.
ChatGPT outperformed the majority of our human humor producers on each task. ChatGPT 3.5 performed above 73% of human producers on the acronym task, 63% of human producers on the fill-in-the-blank task, and 87% of human producers on the roast joke task.
It is unfortunate that researchers keep using the smaller and lower quality gpt-3.5 20B model versus the much larger GPT-4 Classic 1.76T model. They are effectively testing something that is 88 times smaller (and perhaps 88 times worse) than the current state-of-the-art model.
In my time as a human intelligence researcher working alongside Mensa International and the Davidson Academy and many education systems, humor was widely accepted to be a strong indicator of exceptional intelligence (listen to my tribute to Prof Miraca Gross for GE where she talks about this). I await similar testing on GPT-4 (or the current SOTA, Claude 3.5!).
Read the new ChatGPT humor paper via PLOS ONE.
See it on my GPT Achievements Table.
This is another mammoth edition: around 4,000 words, featuring more than 10 new AI toys to play with…